Demystifying Generative AI 🤖 A Security Researcher's Notes


As a security researcher, stepping into the world of Generative Artificial Intelligence (GenAI) was like entering unfamiliar territory. While I was excited by the potential it held for revolutionizing security, I soon realized there were many unfamiliar concepts and terms that were new to me.
In this blog post, I simplify Generative AI concepts and share a few practical applications in security. We start by defining terminology around AI, learn how Neural Networks process language, and explain the role of large language models (LLMs) in modern Generative AI. Along the way, I explain concepts like tokenization, embeddings, retrieval augmented generation, and agents. I hope this helps you and inspires you to build your own tools.
What is Artificial Intelligence (AI)?
AI refers to machines or computer programs capable of processing data and, in more sophisticated forms, learning and improving their responses over time. These AI models range from simple scripts to complex systems that progressively improve by analyzing vast amounts of data.
A little bit of history...
Artificial intelligence has a long history dating back to the 1950s. In 1956, the Dartmouth Summer Research Project on Artificial Intelligence workshop, attended by influential researchers such as John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon, was the first time the term 'Artificial Intelligence' was coined, marking a significant moment in the field.
AI, Machine Learning, Deep Learning? 🤔
After reading about AI, I was a little confused by its distinction from Machine Learning and its relation to concepts like Neural Networks and Deep Learning within generative AI. Let's clarify these terms!
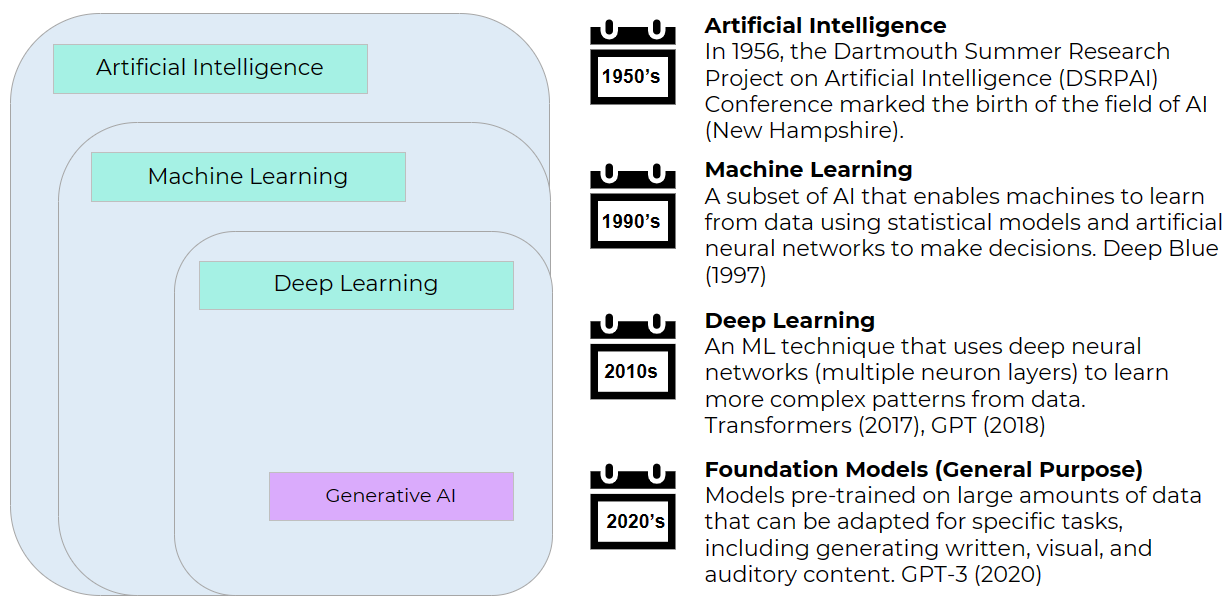
Machine Learning (ML)
Machine Learning (ML) is a subset of AI that connects AI models with data. It helps machines learn from data using methods like statistics and artificial neural networks. This shift has allowed them to transition from following a set of computer instructions to learning from samples of data and recognizing patterns independently, improving their decision-making and predictions over time.
Neural Networks (NN)
A neural network (NN), a type of machine learning model, is like a digital brain composed of simple decision-makers known as neurons. It processes input data, assigns importance (weights) to different parts of the input, uses a default preference (bias), activates decision-makers (activation function), and produces an output. During training, a NN identifies essential patterns in the data, enabling them to provide accurate responses to a task. In inference, a NN applies its acquired knowledge to make decisions.
The conceptual idea of neural networks was introduced in 1943, with Warren McCulloch and Walter Pitts creating a simple neural network to mimic brain functions. However, it wasn't until the 1990s and beyond that this concept truly took off in practical applications, especially in machine learning. This resurgence was fueled by improved algorithms, increased computing power, access to abundant data, practical applications, and enabling technologies.
Deep Learning (DL)
Deep learning, driven by deep neural networks (DNN), is another fundamental machine learning technique in modern AI. It extends neural network principles by incorporating additional layers of decision-makers. This enhancement enables AI systems to understand and learn from increasingly complex patterns of data, resulting in more advanced recommendations.
Deep learning has played an important role in advancing natural language processing (NLP) and driving large language model (LLM) development, revolutionizing our approach to understanding and processing text.
Foundation Models -> Generative AI
Expanding upon deep learning, Foundation Models push this idea even further. They're pre-trained on massive data and built upon deep neural network architectures, stretching the possibilities in the field of AI. Thanks to the advancements in DL, data availability, and computing power, these models can be adapted for various tasks, from generating written, visual, to auditory content. They are fundamental to modern generative AI, powering AI apps.
Artificial Neural Networks 101
After exploring how these concepts were related, I was curious about some of the terminology used when reading about Generative AI models. Words like Parameters, Weights, Hidden Layers, and even Gradients, seemed unfamiliar. I needed to read more about neural networks.
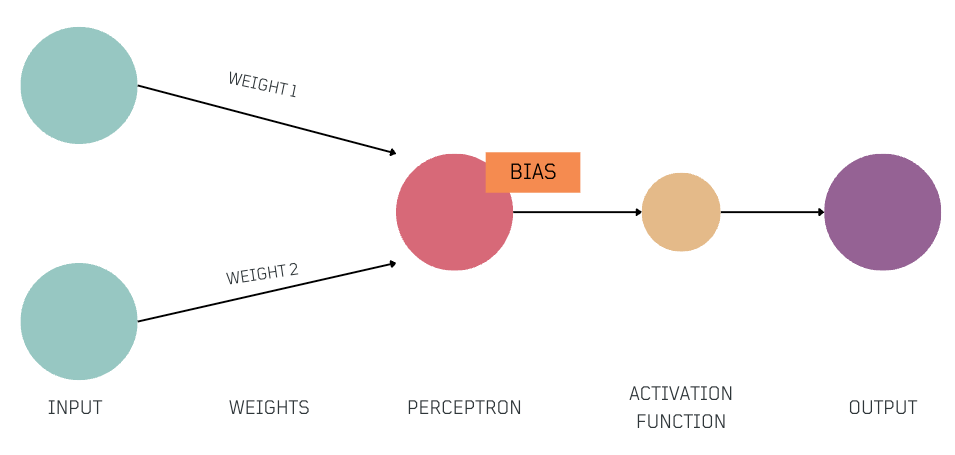
Key Components
- Input: Information received, often represented as numerical values.
- Weights and Biases:
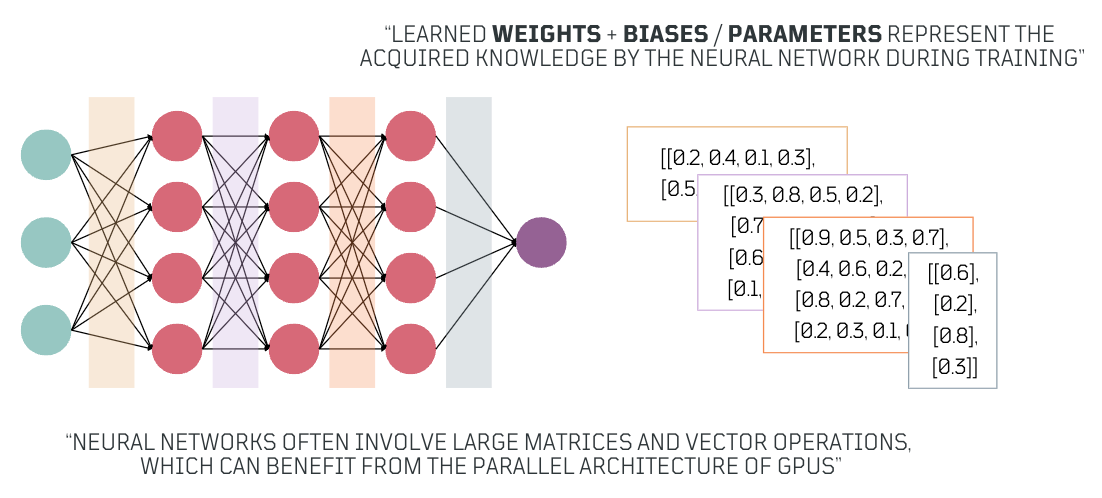
Weightsare numbers that indicate how important various parts of the input data are, andbiasesare numerical preferences that influence decision-making. Together, these values, are known asParameters, and play a critical role in adjusting how the network processes input during training. After training, theseParametersrepresent the acquired knowledge. - Perceptron: Each perceptron acts as a simple decision-maker. It takes the
weighted input, addsbias, and produces anoutput. It's important to note that a single perceptron makes straightforward, linear decisions. Modern neural networks consist of many layers of perceptrons, which enable them to make complex decisions. - Activation Function: The activation function is a key element that introduces non-linearity into the network. It allows the network to capture more complex patterns in the data, helping it to identify important context from the input. This non-linear connection is important for understanding the nuances in the data and making more accurate predictions.
- Output: This depends on the network's specific task and could be a prediction, a classification, or other form of informed response.
Neural Network Layers 🍮
Next, let's break down the concept of layers that form a neural network.
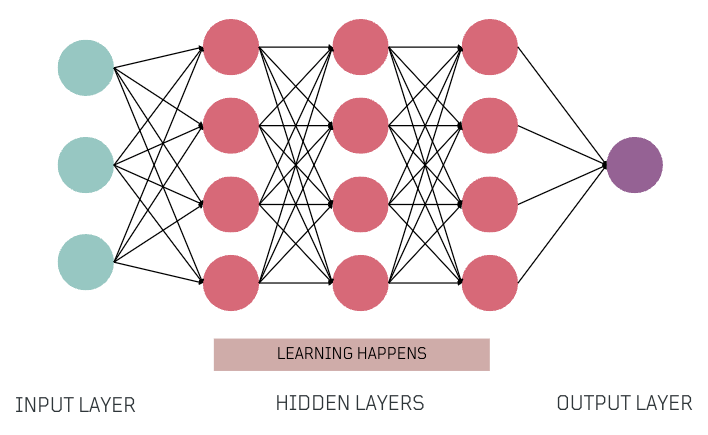
- Input Layer: Receives the numeric representation of the input data.
- Hidden Layers: Intermediate layers where the network learns and extracts patterns from the input data during training, and also very important during inference, helping the network make decisions.
- Output Layer: Layer that produces the network's output, which can be predictions, classifications, or other relevant information.
Training Neural Networks? 🏋🏽♀️
Training is how a model learns from data, adjusting its parameters (weights and biases), getting better at making predictions or classifications. Key training concepts include forward propagation, backpropagation, and gradient descent, which all work together to improve the network's performance.
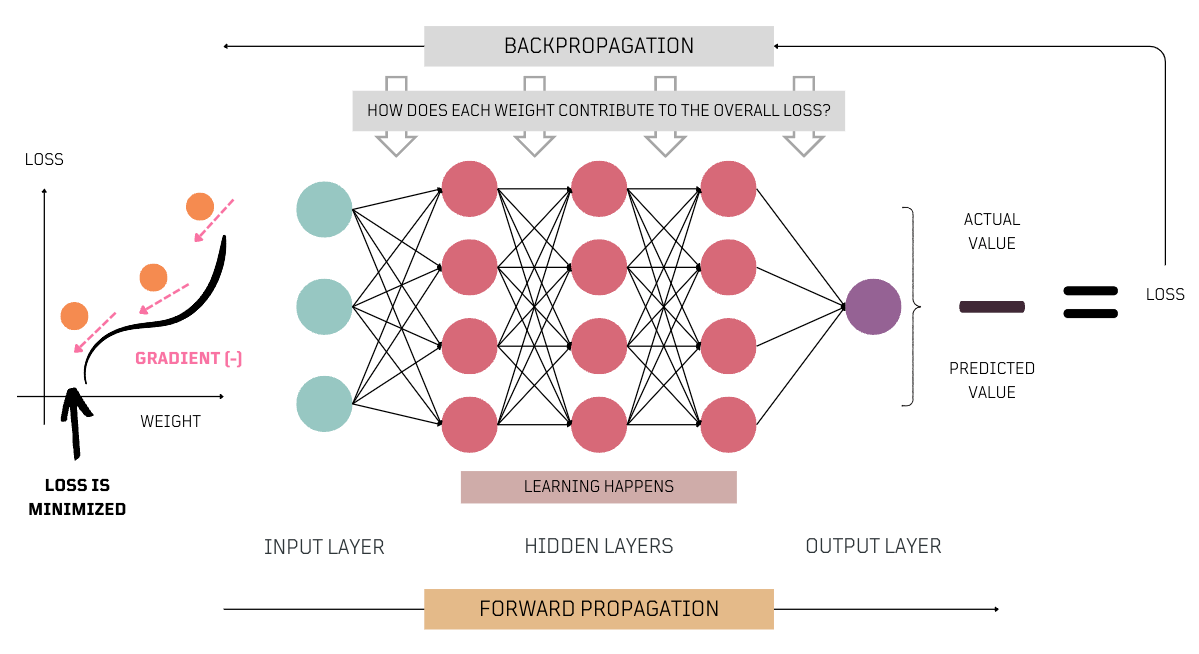
- Forward Propagation: Describes how data flows through the neural network from input to output. Important for both inference and training. During forward propagation, the network processes the input to identify relevant patterns and make informed decisions based on its parameters.
- Backpropagation: A key method used during training. When the network deviates from the expected outcomes, backpropagation helps improve accuracy. It calculates the error at the output and distributes this error backwards through the network. It assesses how each
weightinfluences errors and usesgradientsto guide adjustments, showing how changes in inputs alter outputs. - Gradient Descent: This is a key optimization technique in ML, crucial during the training phase of neural networks. It methodically adjusts the model’s
parameterson gradients calculated duringbackpropagation, making these adjustments incrementally to enhance accuracy and performance.
What Happens after Training? 🧠
After the neural network has minimized the loss to an acceptable level, ensuring reliable performance, the final parameters (matrices of weights and vectors of biases) represent the knowledge it has acquired. These parameters are then used to make predictions on new, unseen data similar to what it was trained on, demonstrating its ability to apply learned insights.
Neural Networks and Language
Even after learning the fundamentals of neural networks, their role in processing language and generating text was still unclear. Understanding how they process sequences like sentences is key to exploring generative AI.
Neural Networks and Sequence of Inputs
In language, neural networks work by handling input as a series of connected words. This word-to-word connection is crucial for understanding the input's meaning. Unlike traditional neural networks, which are good with non-sequential data, language processing requires a more time-based approach.
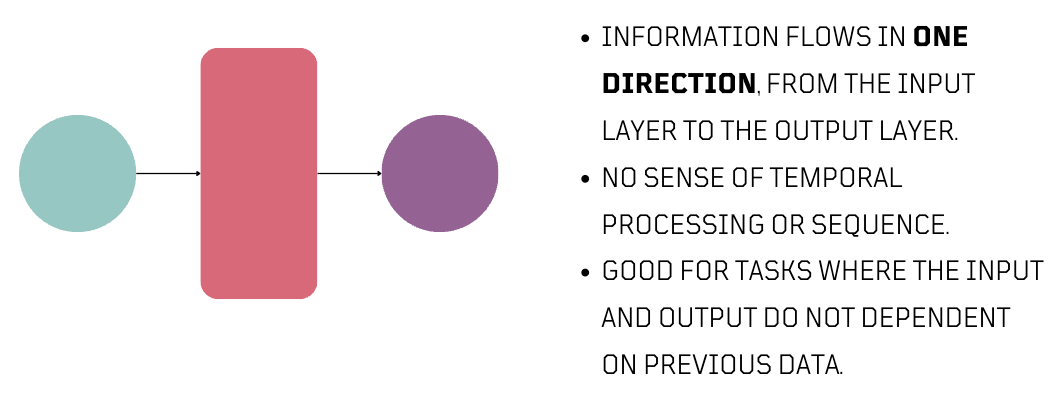
By time-based, I mean that the order and timing of words in a sentence influences its meaning. To effectively understand the nuances of language and generate text, neural networks need to process words in the right sequence.
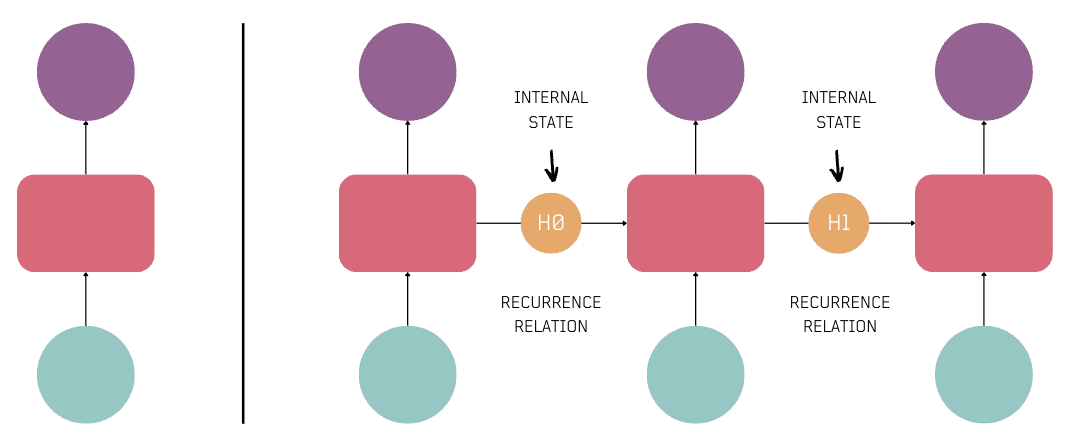
In the image below, each input in a sequence goes through a feedforward neural network. However, the final output doesn't connect with the starting input, because context from each step is not carried over.
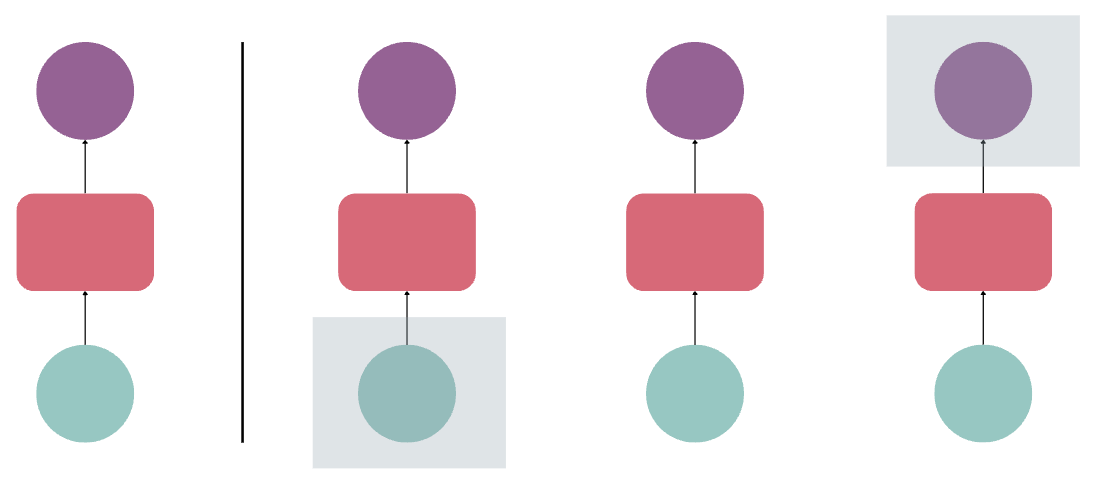
Neurons with Recurrence
Here is where the concept of Recurrence was introduced, allowing neural networks to connect each step and pass on the state to the next iteration. This led to the development of Recurrent Neural Networks (RNNs).
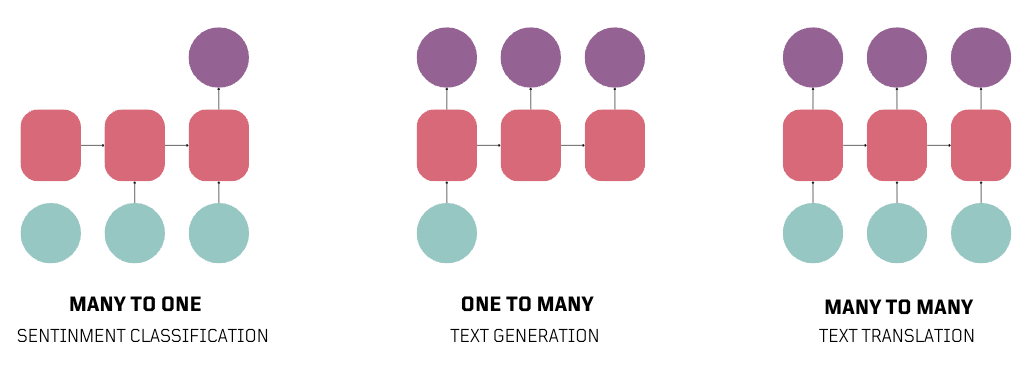
RNNs enable a range of sequence modeling tasks. For example, they can determine the sentiment in a sentence (Many to One), provide descriptions for an image (One to Many), or translate text between languages (Many to Many).
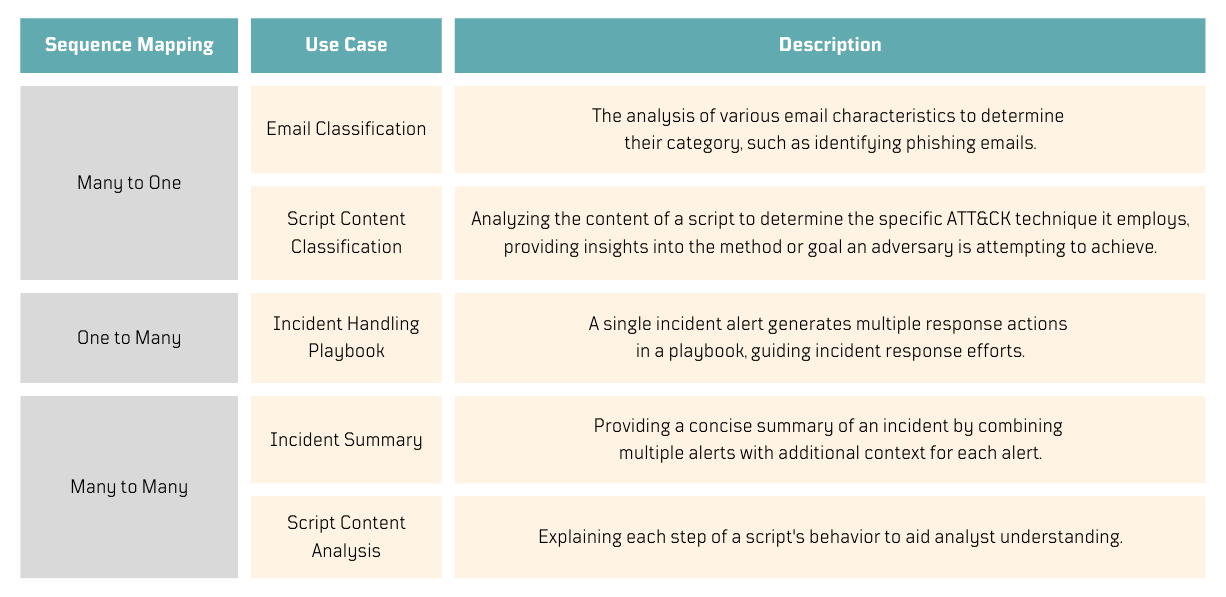
What can we do with that information? 💡
I guess, it started to make more sense how some of these concepts could be applied to the security field. I created the following table to organize my ideas.
Empowering Sequence Processing with Encoder-Decoder
Building upon the principles of RNNs and their ability to capture sequential data, the concept of Encoder-Decoder architectures emerged, setting the stage for more advanced options, such as Transformers, which we'll explore later.

- Two models working together.
- The
encodermodel processes the source language input sequence, producing a fixed-size context vector that captures the input's meaning. - The
context vectorbecomes the starting point for the decoder. - The
decodermodel uses the context vector to generate the target language output sequence step by step, producing one element at a time based on its current state and the previously generated output elements.
How do they consume data? as Raw Text? 🤔
While reading about RNN-Based Encoder-Decoder architectures, I started to wonder if the input processing was as simple as just passing text to them.

Apparently, the input data goes through two key preparation steps, tokenization and embedding, before it's processed by a neural network.
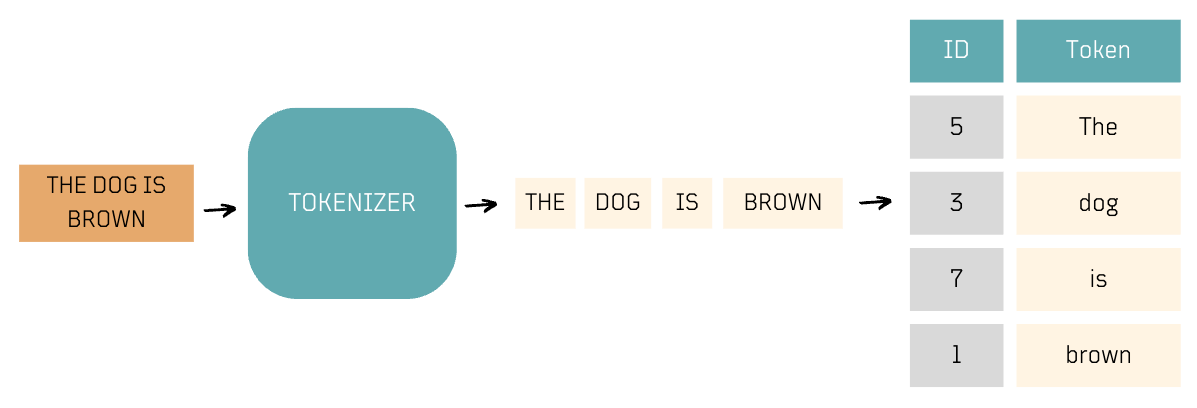
Tokenization
- Tokenization is the process of breaking down raw text into smaller units, such as words or sub-words.
- Tokenization often includes assigning unique IDs, known as token IDs, to tokens, which facilitates the subsequent embedding process, facilitating efficient neural network processing, especially in natural language tasks. These token IDs are typically generated as part of the model's embedding vocabulary.
Embedding
- Embeddings are numerical representations of tokens.
- These representations convert tokens into vectors by capturing their semantic meaning through an embeddings vocabulary with token-to-vector mappings, which the neural network model relies on.
- Embeddings enable neural networks to use meaningful numerical representations of text, capturing both high-level context for sentences or text sequences and individual word or sub-word embeddings. These combined embeddings are utilized by the model for text generation.
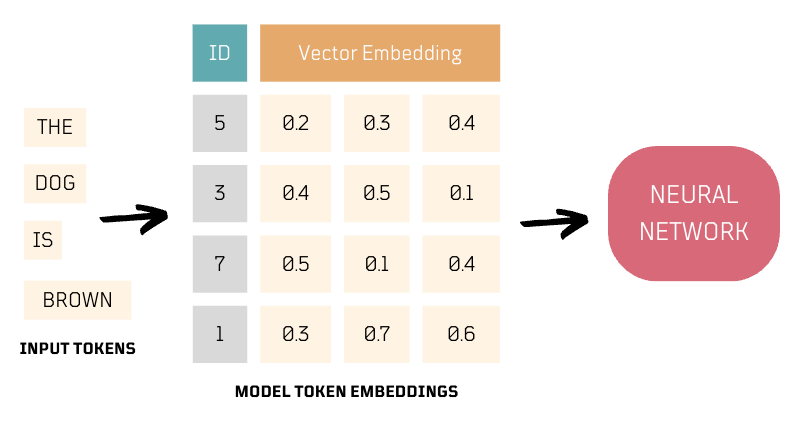
Experiment 1️⃣: Tokenizing and Embedding Text 🧪
Even though I was not familiar with any language models yet 😆, I still wanted to practice and learn how to tokenize and generate embeddings for some text.
For this example, I used the Hugging Face Transformer APIs to download and use the BigBird text model to generate tokens, input Ids and embeddings for a sentence. Simply pip install transformers and run the code below:
Generate Tokens
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google/bigbird-roberta-base")
tokens = tokenizer.tokenize("Hello, my name is Roberto")
print(tokens)['▁Hello', ',', '▁my', '▁name', '▁is', '▁Roberto']
Map Tokens to Input IDs
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)[18536, 112, 717, 1539, 419, 32177]
Add Special Tokens to Input
final_input = tokenizer.prepare_for_model(input_ids)
print(final_input){'input_ids': [65, 18536, 112, 717, 1539, 419, 32177, 66], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
You can see how these Input IDs can be decoded back to text.
print(tokenizer.decode(final_input['input_ids']))[CLS] Hello, my name is Roberto[SEP]
Convert Input IDs to a Tensor and Add Batch Dimension
Transforming Input IDs into a tensor and adding a batch dimension (unsqueeze(0) - specific to PyTorch) is crucial for neural network models. First, tensors are required for efficient matrix computations and leverage hardware accelerators like GPUs. Second, adding a batch dimension adapts the input to the expected format of (batch_size, sequence_length), allowing even single sequences to be processed efficiently in batches, ensuring model compatibility.
import torch
input_ids_tensor_batched = torch.tensor(final_input_ids).unsqueeze(0)
print(input_ids_tensor_batched)tensor([[ 65, 18536, 112, 717, 1539, 419, 32177, 66]])
Load Model from Hugging Face Hub
Download model and set it to use original_full attention type, which is a form of attention where each token in the sequence attends to every other token.
from transformers import BigBirdModel
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")Disable Gradient Calculations
Gradients are not needed for simply making predictions or running the model forward. This improves performance during the inference phase.
with torch.no_grad():
outputs = model(input_ids_tensor_batched)Extract Last "Hidden States" -> Embeddings
The output's last_hidden_state refers to the embeddings from the final layer of the model. They are vector representations of each input token, and they incorporate contextual understanding of the token within its surrounding text.
last_hidden_states = outputs.last_hidden_state
print(f"Token: {tokens[0]}\nIndex ID: {input_ids_tensor_batched[0][1]}\nEmbedding: {last_hidden_states[0][0]} \n")Token: ▁Hello
Index ID: 18536
Embedding: tensor([ 5.6966e-02, 1.6643e-01, 2.1328e-02, -1.3936e-01, 3.5779e-01, 7.9122e-02, -9.8538e-02, 7.5354e-02, 2.4164e-02, ... (cropped)
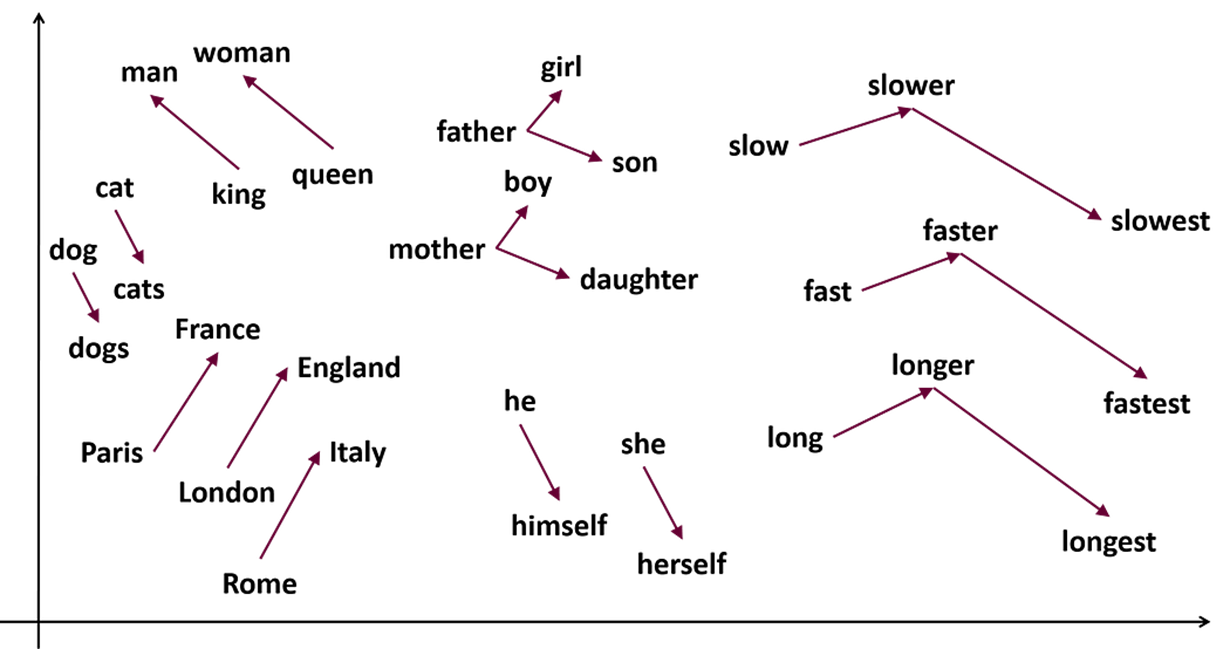
Do similar words share close embeddings? 🤔 Learning about Static vs. Contextual Word Embeddings 💡
While experimenting with text tokenization and embedding, I learned about static and contextual word embeddings. Static models like Word2Vec (Mikolov et al., 2013) generate consistent embeddings for each word, capturing their meanings in isolation. In contrast, contextual models like BigBird adjust embeddings based on the surrounding text, allowing words with similar meanings to appear closer in the embedding space. This dynamic approach not only enhances language understanding and text generation but also captures the overall meaning of sentences through the interactions between words.
Experiment 2️⃣: Visualizing Static Word Embeddings in 2D 🧪
For this experiment, I used the word2vec-google-news-300 model (~2GB) to embed words as vectors and apply Principal Component Analysis (PCA) to demonstrate how semantically similar words cluster together in a 2D plot.
Download Word2Vec Model
We start by downloading the model trained on part of the Google News dataset, covering approximately 3 million words and phrases.
import gensim.downloader as api
model = api.load('word2vec-google-news-300')Select Words and Extract Embeddings
# List of words to visualize
words_list = [
'dog', 'dogs', 'cat', 'cats', 'man', 'king', 'woman', 'queen', 'dad', 'father', 'girl', 'son',
'mom', 'mother', 'boy', 'daughter', 'slow', 'slower', 'slowest', 'fast', 'faster', 'fastest',
'long', 'longer', 'longest', 'short', 'shorter', 'shortest', 'he', 'himself', 'she', 'herself',
'Rome', 'Italy', 'London', 'England', 'Paris', 'France', 'rich', 'poor', 'queen', 'king', 'fisherman',
'teacher', 'actress', 'actor'
]
# Extracting embeddings
embeddings = [model[word] for word in words_list]Reduce Dimensionality with PCA
To visualize high-dimensional data on a 2D plot, we use Principal Component Analysis (PCA) to reduce the dimensions of our word embeddings. PCA helps in capturing the most significant variance among the words, making it easier to interpret their relationships visually.
from sklearn.decomposition import PCA
# Applying PCA to reduce dimensions to 2D
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(embeddings)Visualize Word Embeddings
import matplotlib.pyplot as plt
# Plotting
plt.figure(figsize=(12, 7))
plt.axvline(color='gray')
plt.axhline(color='gray')
# Annotating each point with its word label
for i, word in enumerate(words_list):
plt.scatter(embeddings_2d[i, 0], embeddings_2d[i, 1], label=word)
plt.annotate(word, (embeddings_2d[i, 0], embeddings_2d[i, 1]), textcoords="offset points", xytext=(0,10), ha='center')
plt.title('Word Embeddings Visualization')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.grid(True)
plt.show()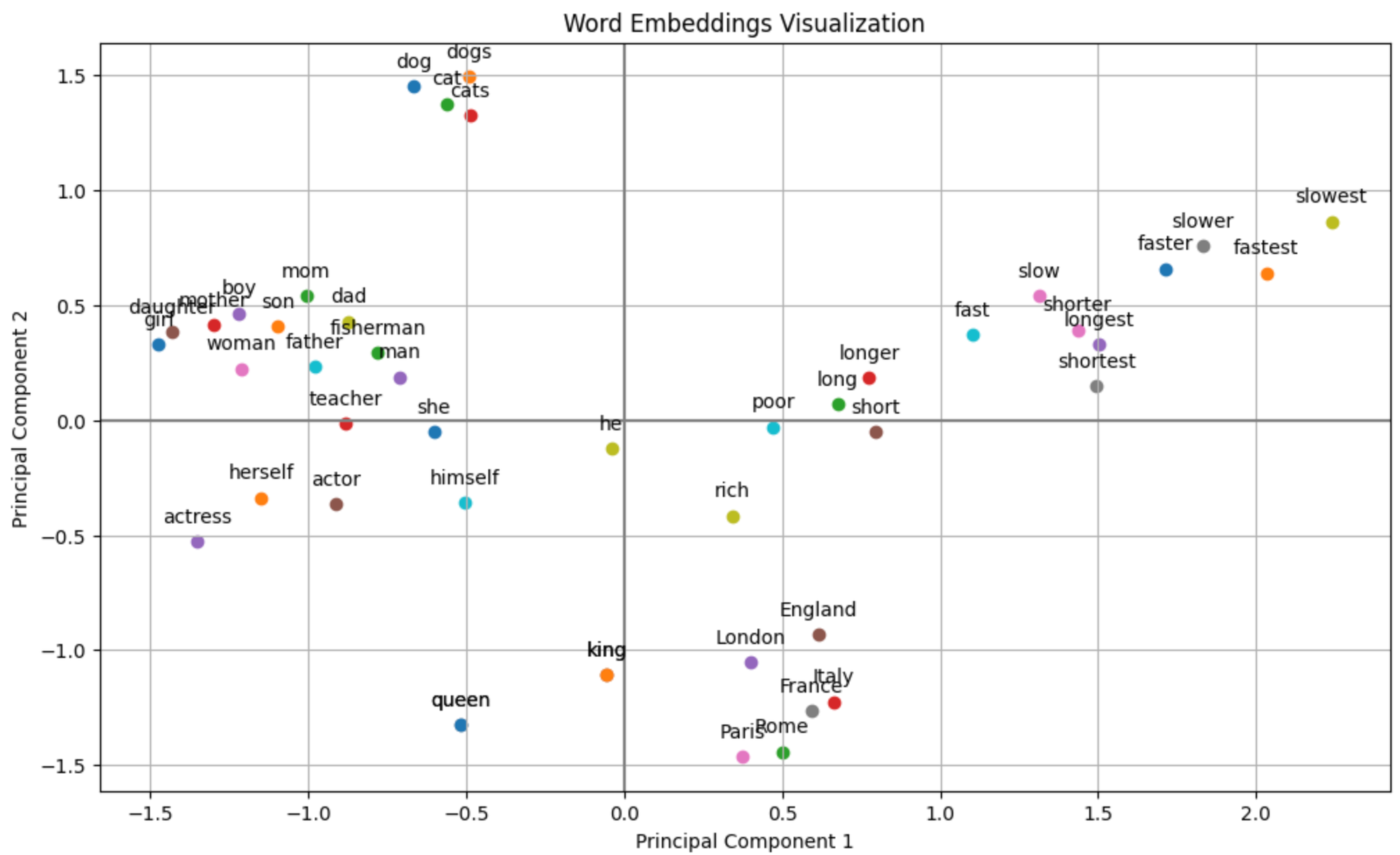
Experiment 3️⃣: Can we tokenize and generate embeddings for a security event log? 🧪
The short answer is Yes! However, I learned that not all models can do it efficiently because security event logs have a different structure than regular sentences. It may be necessary to train a model from scratch to tokenize security event logs and generate embeddings for a more accurate representation.
I used the same Hugging Face Transformer APIs to download and use the BigBird text model to tokenize and generate embeddings for a security event log.
 OTRF
OTRF
RNN-Based Encoder-Decoder Disadvantages
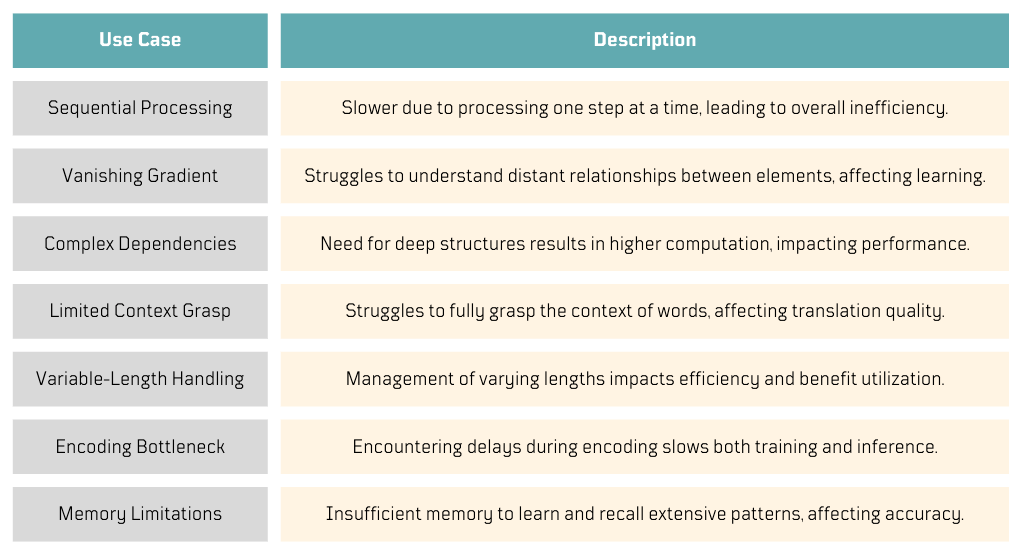
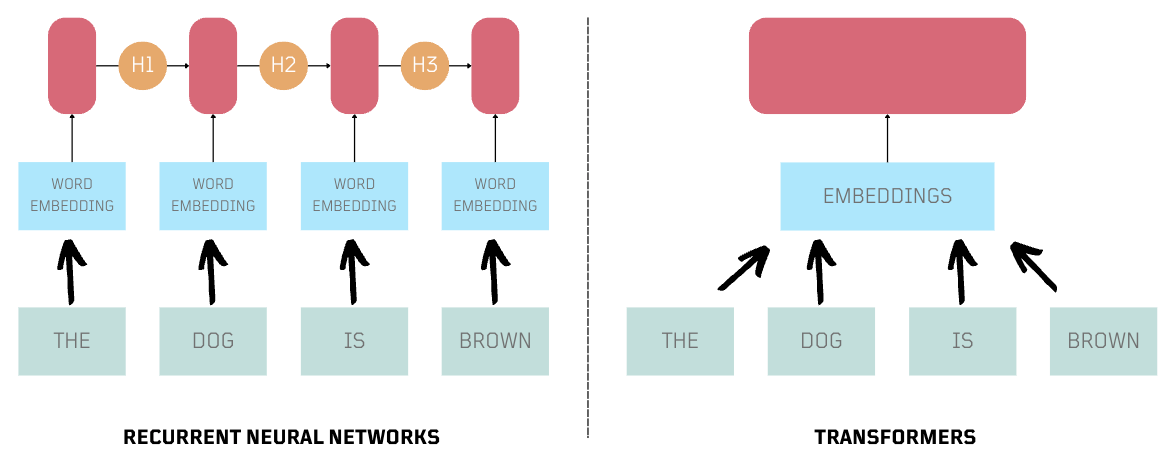
While reading about tokenization and embeddings, I noticed that RNN-based Encoder-Decoder models were not frequently mentioned in the latest approaches for processing large texts in generative AI 🤔. As I was updating my notes, I started to realize their limitations, especially when dealing with large texts, as they process one embedding at a time. Can parallelism help here?
It turned out there were more limitations I didn't know about.
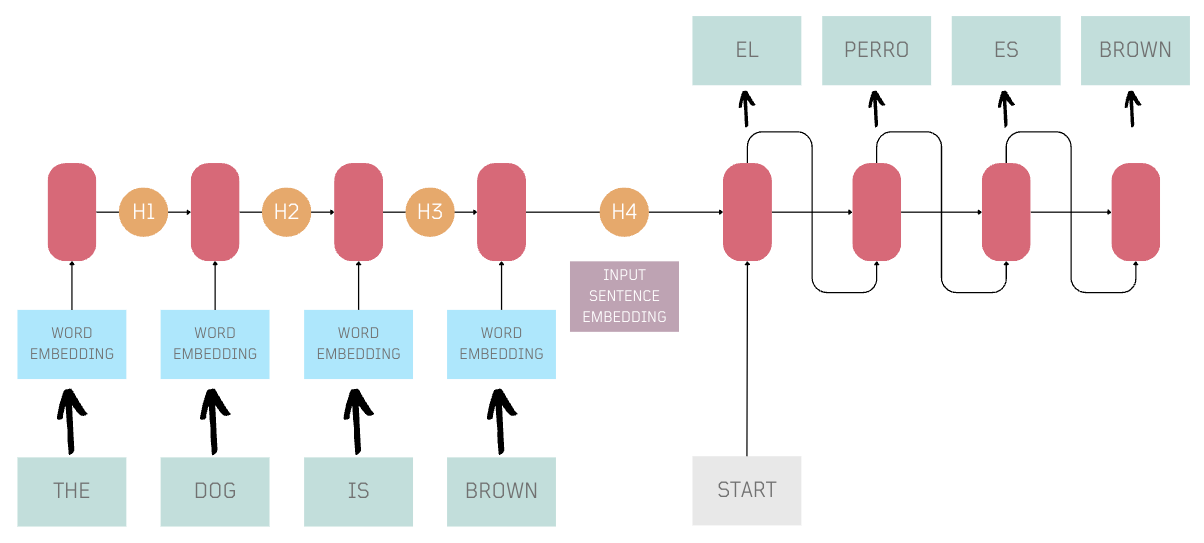
Enter Transformers 🤖
In 2017, researchers at Google introduced groundbreaking method to overcome the limitations of the initial RNN-based encoder-decoder. This innovative approach, outlined in the paper 'Attention Is All You Need', introduced a novel encoder-decoder architecture known as Transformers.
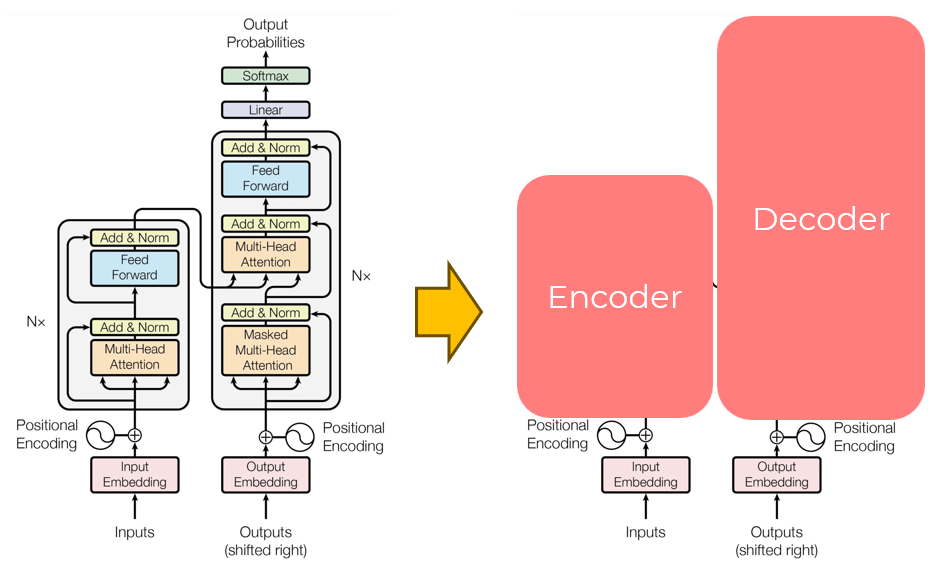
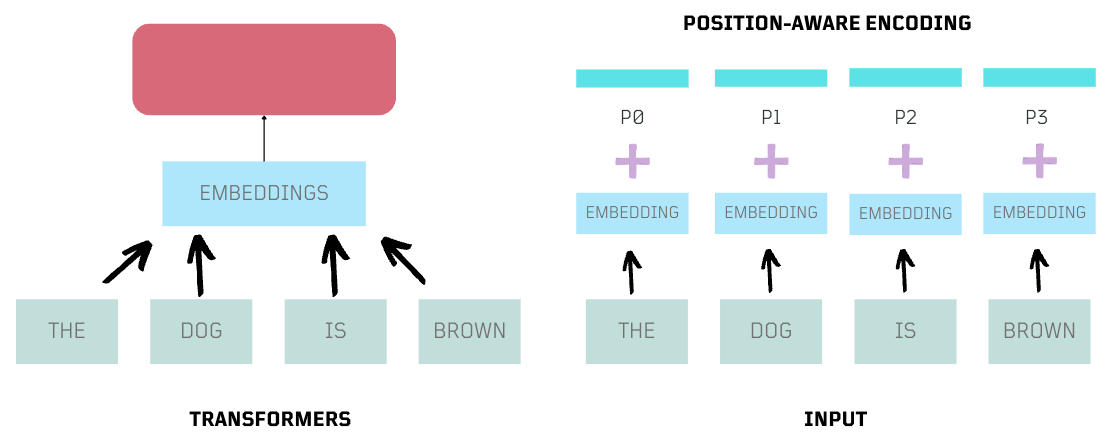
Transformers introduced parallel processing, positional encoding, and self-attention, marking a significant leap in how we work with language.
Parallelism (No Recurrence)
Sequential processing can pose challenges in capturing long-range dependencies effectively. Transformer-based models offer the advantage of parallel processing but are constrained by a maximum token count, a limitation frequently mentioned in the context of the latest Large Language Models (LLMs).
Positional Encoding
Parallelism greatly improved input processing but removed the order of words in sequential modeling. Transformers introduced positional encoding, appending context to embeddings, allowing the model to understand word positions.
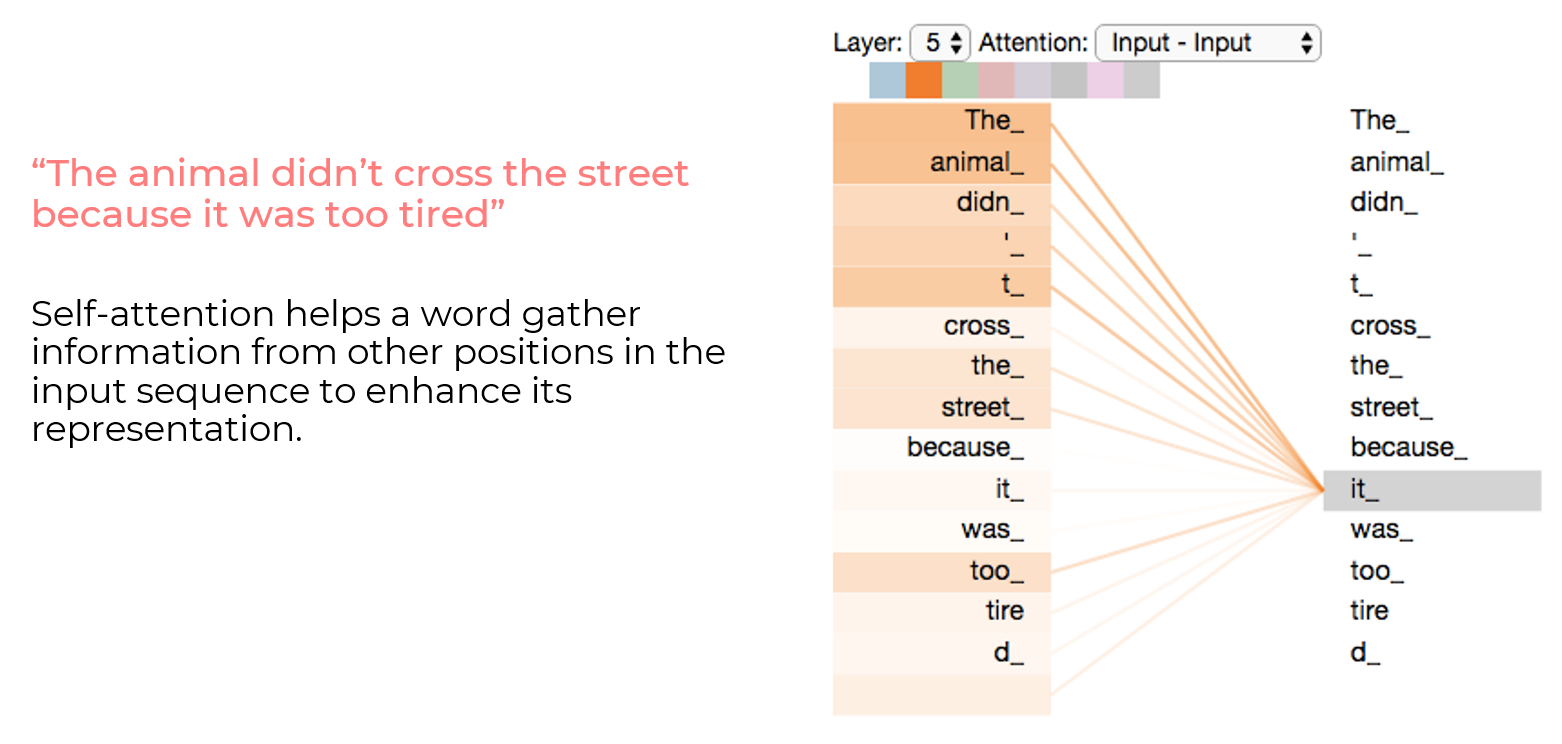
Self-Attention
In addition to parallelism and positional encoding, transformers introduced self-attention. Self-attention in transformer-based models works like words in a sentence helping each other understand their importance and context, improving the model's understanding of text meaning. In the example below, the word it has a stronger relationship with animal than with street.
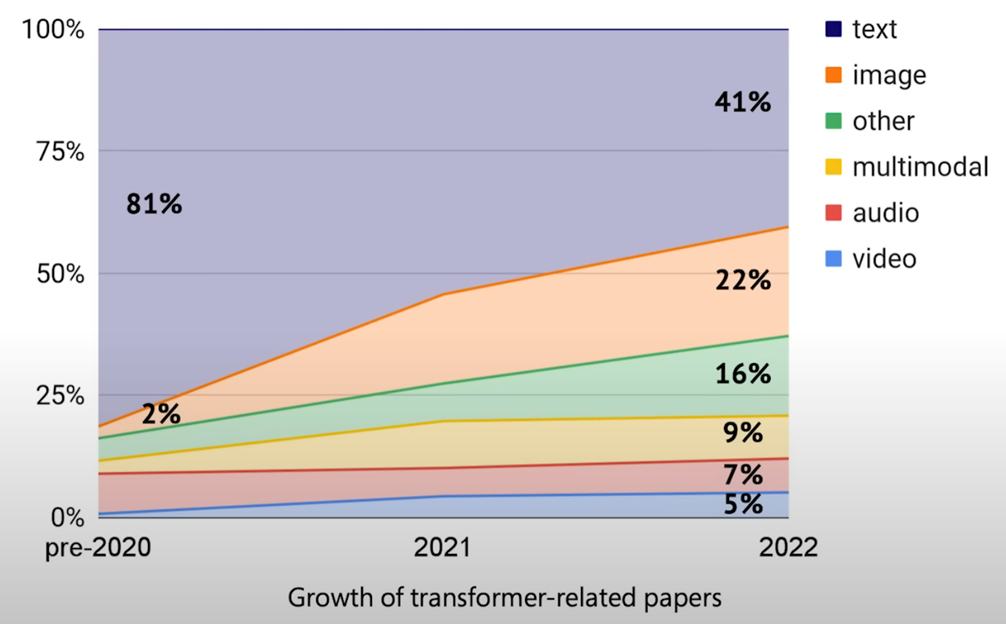
This transformer-based architecture has gained immense popularity, extending its use beyond text to images, audio, and video. This highlights the versatility of transformers as a cross-modal general architecture.
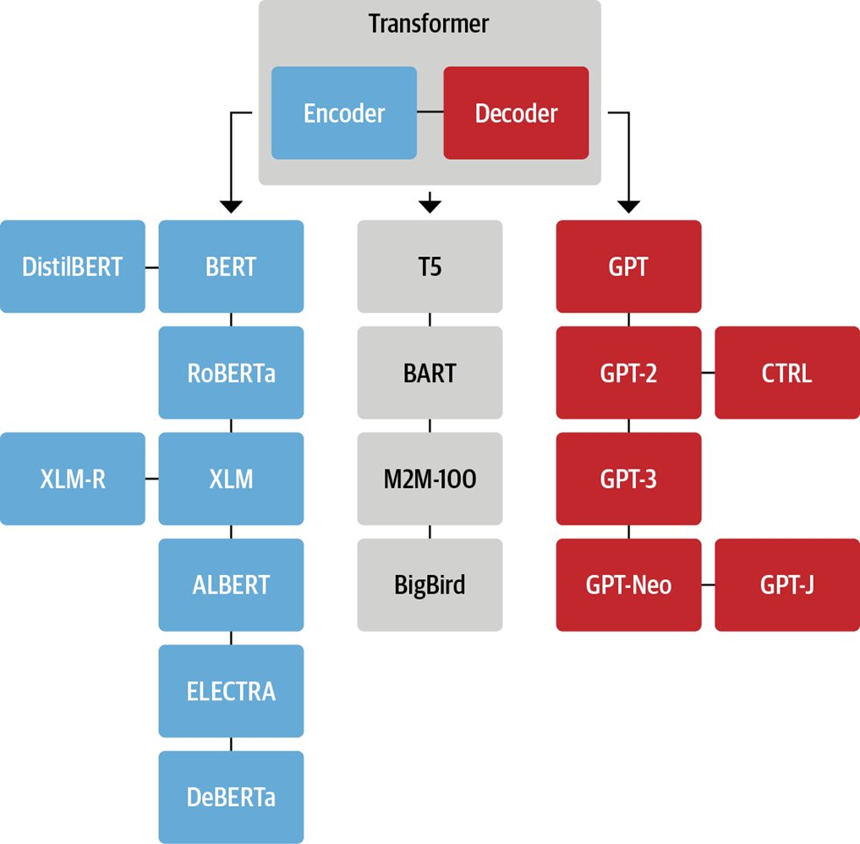
Can a transformer-based model be an encoder only?
Yes! Encoder-only models process input data, Decoder-only models generate output, and Encoder-Decoder models handle both input and output.
General Purpose AI Models
Transformer's innovative approach enabled the training of large models, often referred to as foundation or general-purpose models. These models are capable of understanding and processing various data types, contributing to significant advancements in generative AI and beyond.
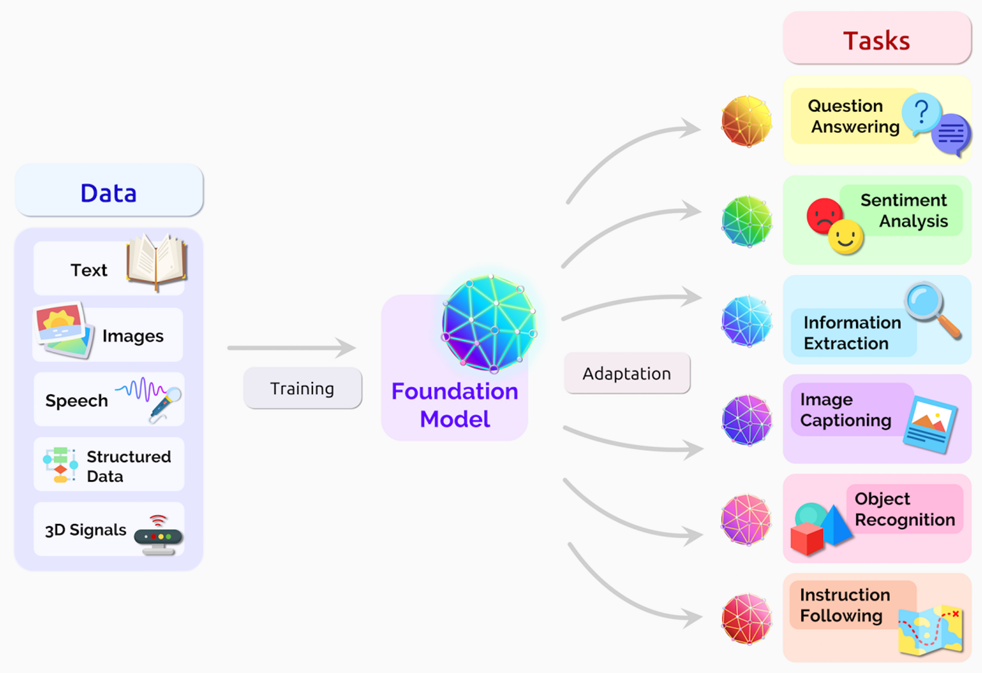
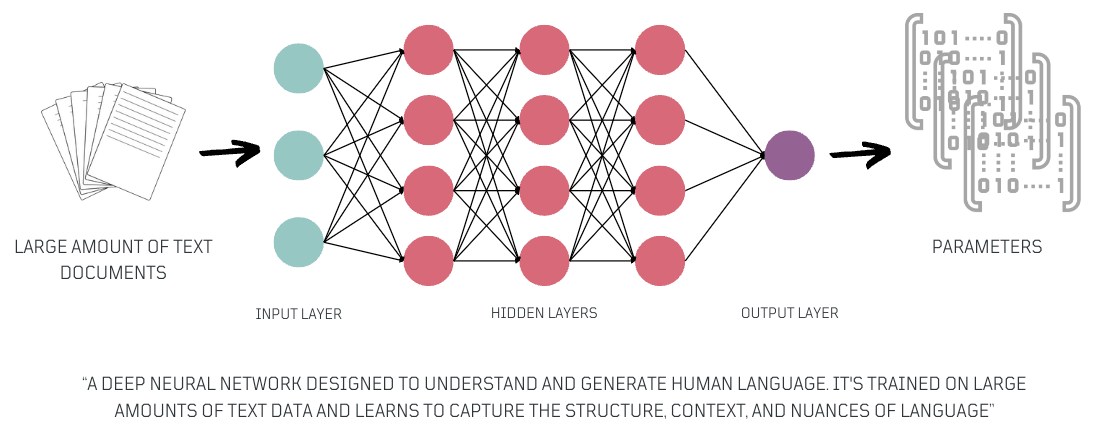
Large Language Models (LLMs)
Large language models are a specific type of general-purpose model, primarily text-based, that have significantly contributed to the advancement of generative AI. These models, trained in large amounts of data, have emerged as powerful tools for various Natural Language Processing (NLP) applications. They excel in tasks like natural language understanding and text generation.
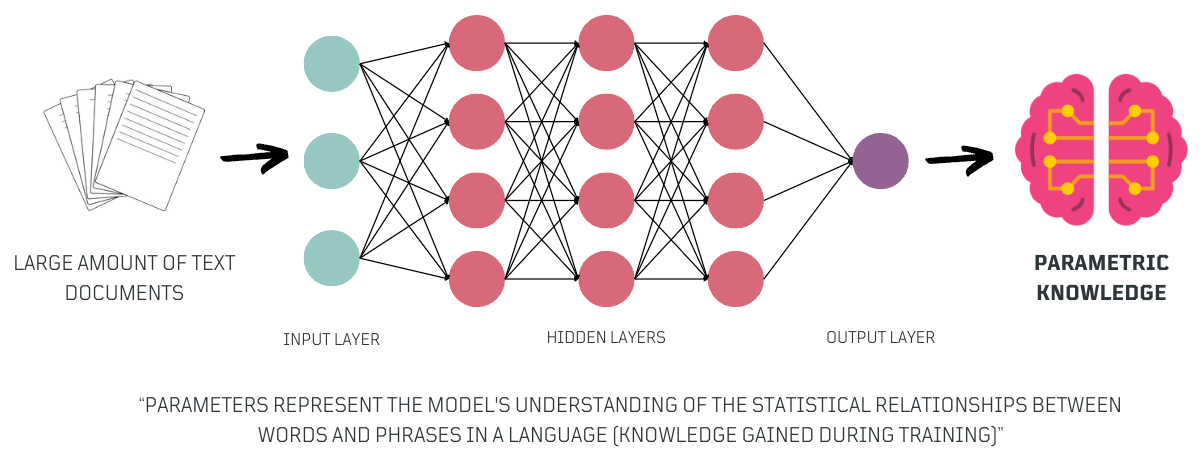
The parameters of these models, often referred to as Parametric Knowledge, encapsulate the model's understanding of language 😎.
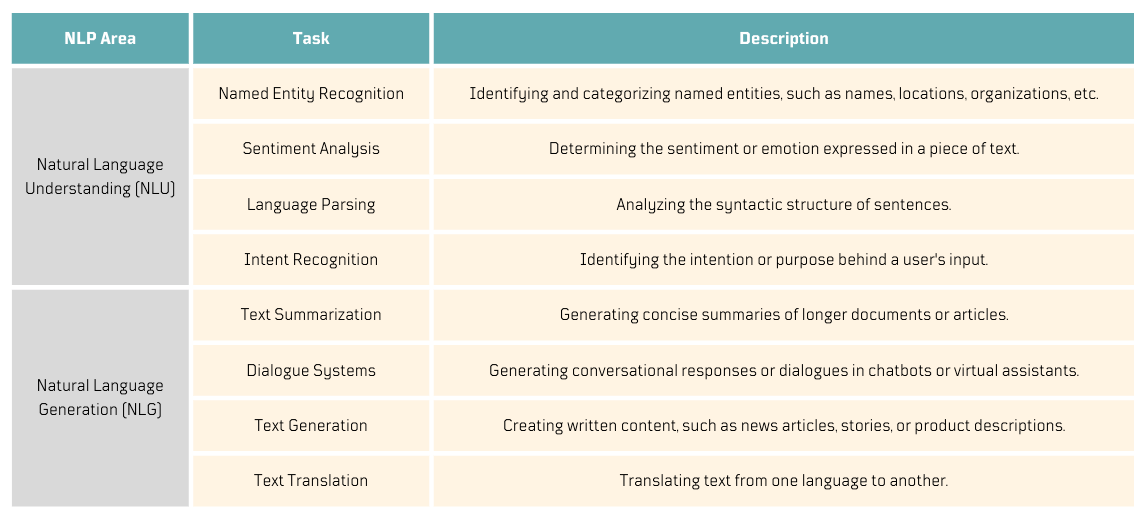
How can I organize these out-of-the-box NLP abilities?
LLMs can handle numerous NLP tasks. I wanted to find a way to organize my experiments, and I think this is a good reference to help you categorize your own.
Two Types of Large Language Models (LLMs)
Now, this was interesting. I assumed that LLMs could right away start answering questions based on their training data and understanding of language. Nope!
Base LLMswere initially trained to predict the next word by processing large amounts of data using a self-supervised approach, filling in missing words in text. However, they couldn't naturally comprehend questions or instructions as humans do, which make it tricky to interact with them.- To address this,
Instruction-Tuned LLMsemerged. These models werefine-tunedfrom base LLMs to comprehend instructions or questions, enabling them to generate contextually relevant responses. Thisfine-tuningimproved their ability to engage in conversational exchanges.

Transfer Learning: What is Fine-Tuning?
While reading about LLMs, I noticed the concept of fine-tuning appearing frequently, not realizing it was an important part of transfer learning. Transfer learning, in simple terms, allows models to effectively tackle new tasks by building upon their acquired knowledge. With LLMs, this involves initially training a model on a large dataset and then refining it for specific tasks.
The word Pretrained was also coming up frequently, and it was at this point that its connection to fine-tuning started to make more sense.
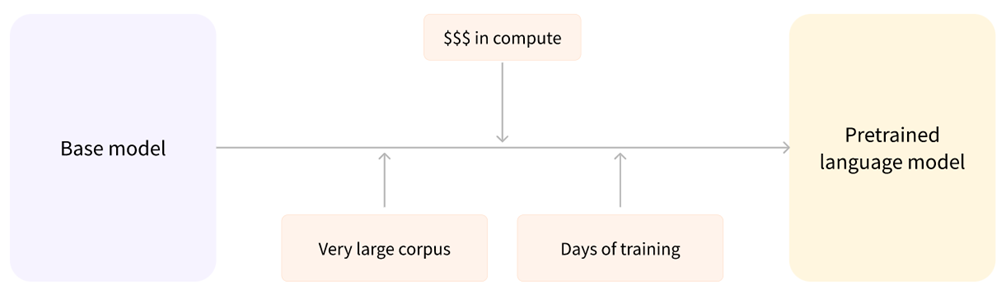
Pretrained Language Models
Pre-trained language models are foundational models created by training on large amounts of data, requiring substantial computational resources and days of training. These models serve as a basis, providing foundational knowledge for more specific tasks, achieved through fine-tuning.
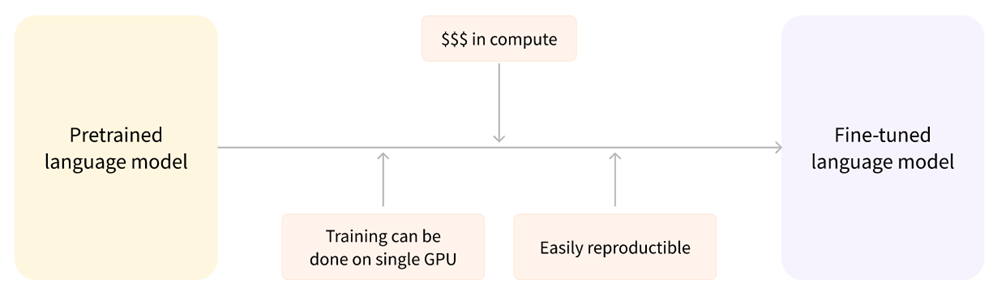
Fine-Tuned Language Models
Fine-tuned language models are like tailored versions of pre-trained models, meticulously adjusted for specific tasks. The training can be accomplished on a single GPU, making it cost-effective and easy to replicate.
Wait! Generative Pre-trained Transformer (GPT)? 😎
GPT makes more sense now! 😅
- A type of
LLMtrained to predict subsequent words in sentences. Pre-trainedon vast unlabeled text using self-supervised learning.- A
Transformer-based decoder-onlymodel. - Optimized for chat interactions while also performing well in traditional completion tasks (i.e., text generation).
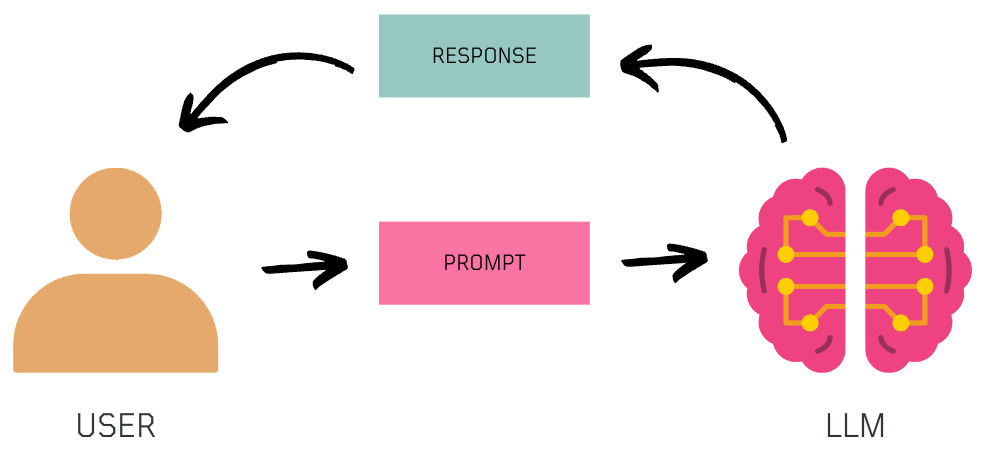
So, how do we talk to LLMs? 🗣️
Through prompts! By giving them specific instructions through prompts, we can generate the content / response we want.
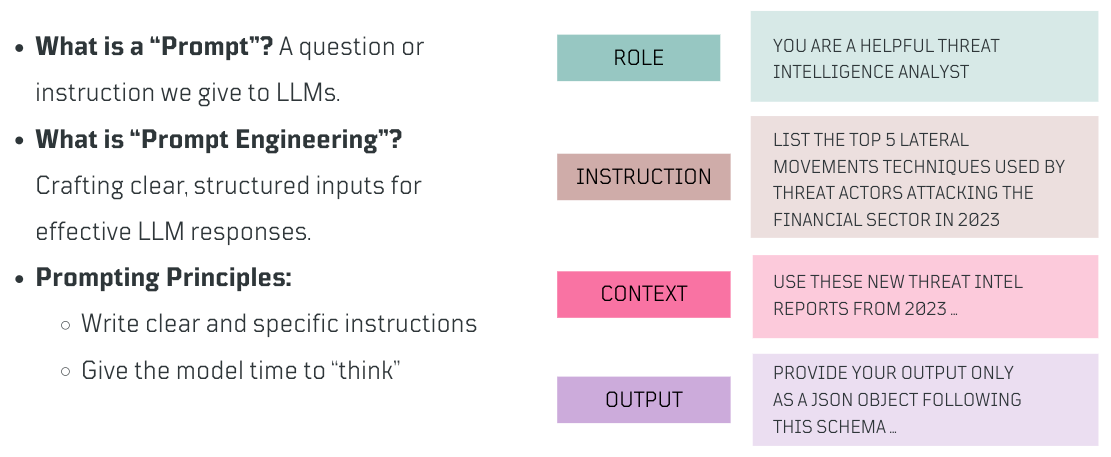
When crafting a prompt, consider defining the role, an instruction, the context, and the output format to guide the model effectively. The role sets the context for the interaction, the instruction guides the model on what task to perform, the context offers additional information, and defining the output specifies the desired response, ensuring a well-structured interaction with the LLM.
Experiment 4️⃣: How can I ask a question to an LLM? 🧪
At this point, I was already getting more familiarized with a few public LLMs, so I decided to try one from GPT4All, an open-source ecosystem to train and deploy large language models that run locally on consumer grade CPUs.
For this experiment, I downloaded the orca-mini-3b-gguf2-q4_0.gguf instruction-based model from the GPT4All site, installed langchain and gpt4all python packages, and ran the following python code:
from langchain.llms import GPT4All
# Initialize Model
llm = GPT4All(model='./model/orca-mini-3b-gguf2-q4_0.gguf')
# Define Prompt
prompt = "Where is Peru?")
# Pass prompt to LLM to generate text
llm("Where is Peru?")'Peru is located in the western coast of South America, bordering Ecuador, Colombia, Brazil, Bolivia and Chile. It has a diverse geography that ranges from the Andes Mountains to the Pacific Ocean. The capital city of Peru is Lima, which is also its largest city.'
LLMs are Few-Shot Learners!
Did you know that when interacting with LLMs through text prompts, you can utilize various approaches, including "zero-shot" and "few-shot" techniques.
- In
zero-shotscenarios, models generate content without specific examples or training data for a task, relying solely on the provided prompt. - In
few-shotscenarios, LLMs perform tasks with minimal examples, allowing them to adapt to new tasks or generate content effectively with just a handful of examples or instructions.
How does that help? 🤔
Traditional ML requires labeling and training data for predictions. In contrast, prompt-based models allow us to use natural language prompts for direct predictions, making it easier to create ML models like classifiers with only a few examples in the prompt, simplifying the process.
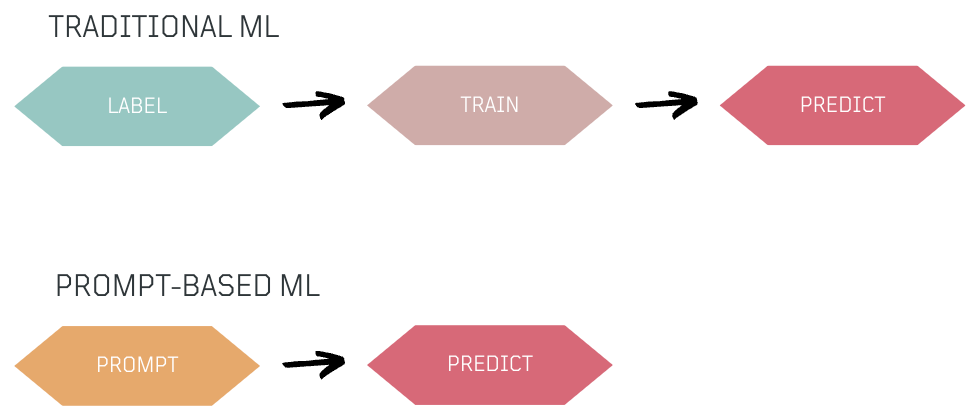
Experiment 5️⃣: How can I build a sentiment classifier? 🧪
A sentiment classifier is a type of ML model that is trained to determine the sentiment of a piece of text, such as positive, negative, or neutral. To keep it simple, I wanted to create a demo to classify if the subject of an email was benign or malicious. This of course can be extended to cover more context from an email.
For this experiment, I use the same orca-mini-3b-gguf2-q4_0.gguf instruction-based model from GPT4All, and langchain and gpt4all python packages.
from langchain.llms import GPT4All
# Model downloaded manually from https://gpt4all.io/index.html
llm = GPT4All(model='./model/orca-mini-3b-gguf2-q4_0.gguf')
prompt = """
Classify the email subject text below, delimited by three dashes (-),
as being malicious or benign. Explain why.
---
Account email verification code, enter now and reply
---
"""
llm(prompt)This email is likely to be considered as a phishing attempt because it requests the recipient to provide an account verification code that they may not have received from the actual email provider. Additionally, the email does not contain any legitimate information or context that would make the recipient believe that this is a genuine request for account verification. Therefore, it can be classified as malicious.
The model classified the email subject as phishing when there was not much context. It is either hallucinating 😆 or using facts from its training dataset.
I decided to experiment with another model and ended up using OpenAI gpt-3.5-turbo to extend the example and show Zero-Shot and Few-Shot. The idea was to provide examples to my prompt and influence the classification.
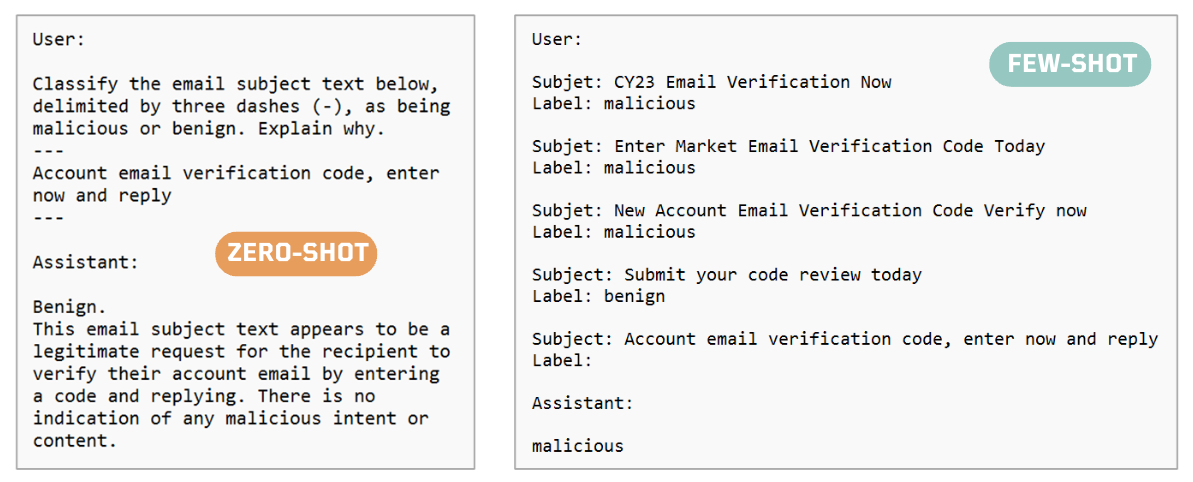 OTRF
OTRFAny Constraints with LLMs? 😱
Something I didn't initially realize about LLMs was some of their limitations:
- Knowledge Coverage: How much they know about different topics.
- Timeliness: How current the information is.
- Personalization: The inability to provide private or personalized data.
- Hallucinations: Instances where the generated content lacks factual basis due to guessing or speculating beyond available data.
Knowledge Coverage? Timeliness? What do you mean? 🤔
Let's say you want to know about a specific ATT&CK technique and ask ChatGPT about it. Depending on the ATT&CK technique, you might get a similar response.
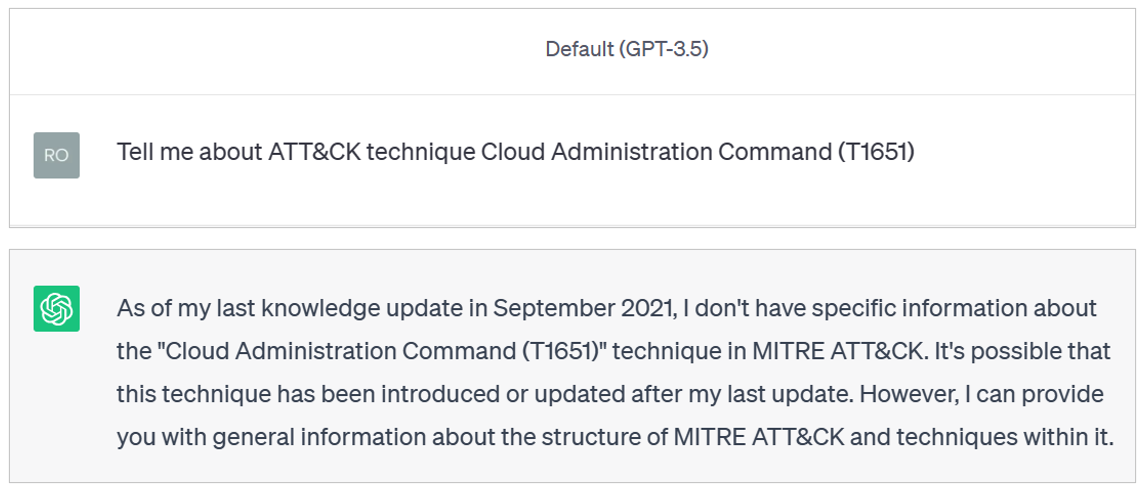
Yup! That specific technique was added to ATT&CK in April 2023.

Hallucinations? What do you mean? 🤔
What if the LLM tries to explain something that was not part of its training data? Let's say we want to know about ATT&CK technique Financial Theft (T1657) (added in October 2023). In the chat below, the LLM hallucinates and states that T1657 is related to Dynamic Data Exchange and not Financial Theft 💀

Enter Retrieval Augmented Generation (RAG)!
To overcome these limitations, a promising technique exists known as Retrieval Augmented Generation (RAG). A technique that combines information retrieval with text generation, allowing a language model to use external information as context to enhance the quality and relevance of generated text or response.

What does a Basic RAG Flow look like?
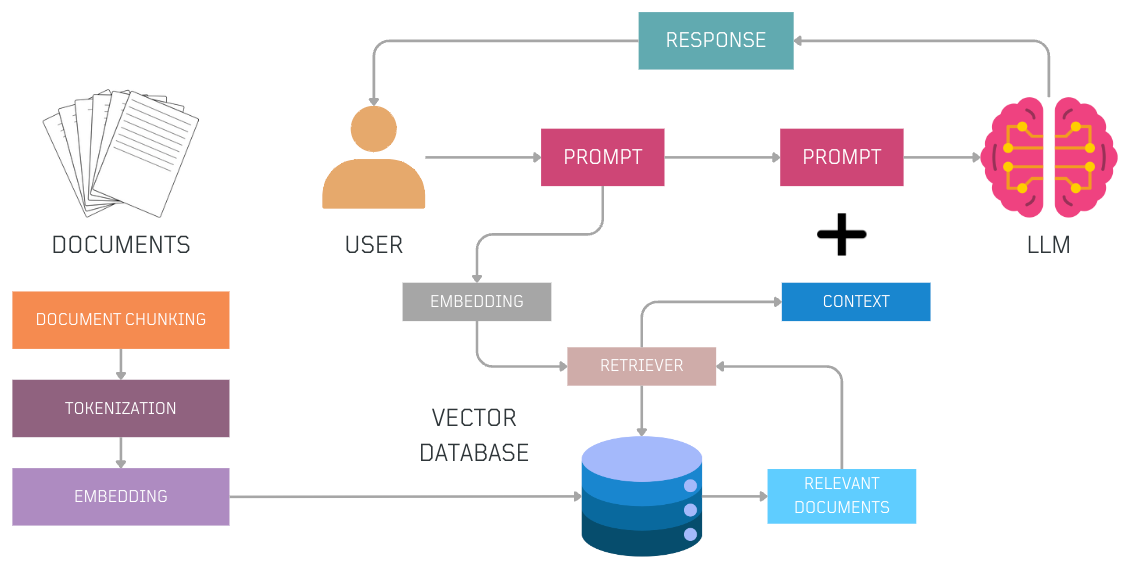
- Source knowledge is tokenized and embedded. These embeddings are stored in a vector database and are available to the LLM to be used as additional context.
- The user begins by asking a question.
- The question is converted into numerical vectors (tokenized and embedded).
- The retriever conducts a similarity search within the vector database containing embedded knowledge from various sources.
- Relevant documents similar to the user's question are retrieved.
- The user combines the original query and the retrieved documents (context) to create a more informative prompt and pass it to the LLM.
- With the additional context, the LLM generates a more accurate and context-aware response to the user's query.
Experiment 6️⃣: Can I query my own Threat Intelligence then? (Private Data) 🔒 🧪
I wanted to showcase a simple RAG flow for querying private data in the context of cybersecurity, so threat intel data seemed to be a good use-case. To show this idea, I decided to use ATT&CK groups, which represent clusters of public threat activity linked to specific groups, as a way to mimic an organization's TI.
I will write another blog post explaining everything in more details 😎, but for now, I can share a few notebooks to show how to download ATT&CK groups, store their embeddings in a vector database and use it with a RAG workflow.
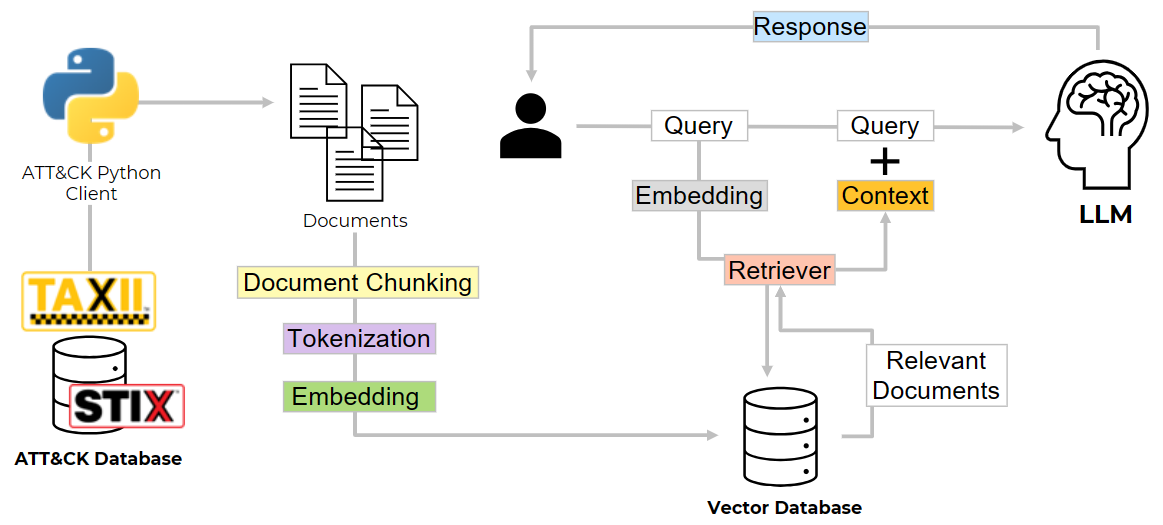
1) ATT&CK Groups -> Tokens -> Embeddings -> Vector DB
OTRF2) RAG ATT&CK Groups Context
OTRFHow can I build tools with LLMs? 🦾🤖
After learning some of the fundamentals, I decided to explore how to create an assistant/agent that uses LLMs to help it decide when to use a specific function or tool and generate structured output for the tool to use as input to perform a task.
Experiment 7️⃣: Can an LLM help me call an API? 🤯 🧪
I will write another blog post explaining everything in more details 😎, but for now, the idea is to create an assistant/agent that understands the Microsoft Graph API OpenAPI specs and converts natural language into API calls to interact with it. This reduces the amount of code I used to write to call the API 🤯.
The Basic Idea!
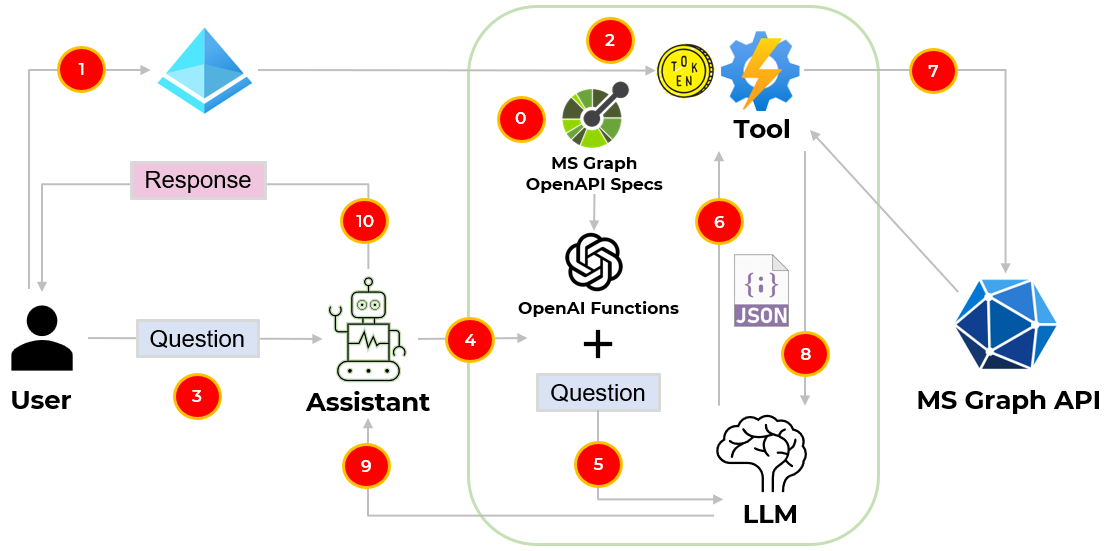
- We take the MS Graph API OpenAPI specification and transform it into a list of OpenAI functions to have our LLM intelligently choose to output a JSON object containing arguments to call those functions 🚀.
Userinteractively authenticates with Microsoft Entra ID via the authorization code authentication flow to retrieve an access token for the MS Graph API.- Access token is set on the
toolauthorization header to query MS Graph APIs. Useruses natural language to task theassistantwith an action.Assistanttakes the prompt and appends the MS Graph API OpenAI functions.- The
enriched promptis passed to theLLMto decide what API to use based on the prompt and the MS Graph API OpenAI functions. LLMpicks the right API for the task and produces a structured output with the right API parameters and values related to the initial prompt.- The
toolprocesses the parameters and values produced by theLLMand calls the MS Graph API. - The
toolpasses the MS Graph API response to theLLM. - The
LLMsummarizes the response and passes it to theassistant. - The
assistantpasses the response to theuser.
For this experiment, I use OpenAI GPT4 model, OpenAI function calling, langchain and MS Graph API OpenAPI specs for the Users endpoint. I am still trying to figure out how to make the LLM work with a larger OpenAPI spec.
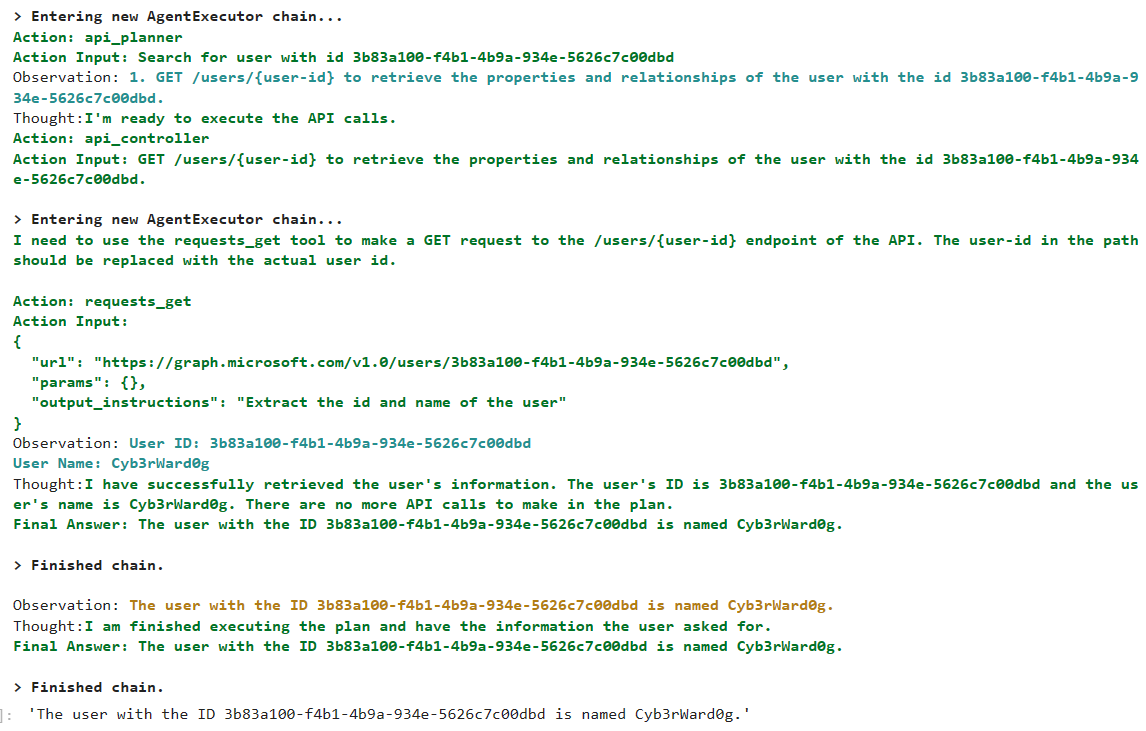
OTRFTake a look at the results 🤯!
What's next? 🤖🛡️
The beginning ...
Congrats for making it this far! Time for you to write your own adventure!

Stay up to date with this journey! https://github.com/OTRF/GenAI-Security-Adventures
References
- A Brief History of Neural Nets. Important dates in the History of… | by Frauke Albrecht | Towards AI
- One the Opportunities and Risks of Foundation Models: 2108.07258.pdf (arxiv.org)
- MIT Introduction to Deep Learning: https://www.youtube.com/watch?v=QDX-1M5Nj7s&t=5s
- What are Generative AI Models: https://www.youtube.com/watch?v=hfIUstzHs9A
- Visual Prompting Livestream with Andrew Ng: https://www.youtube.com/watch?v=FE88OOUBonQ&t=129s•Tensor2Tensor Intro - Colaboratory (google.com)
- Understanding Encoder-Decoder Sequence to Sequence Model | by Simeon Kostadinov | Towards Data Science
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation https://arxiv.org/pdf/1406.1078.pdf
- Sequence to Sequence Learning with Neural Networks https://arxiv.org/pdf/1409.3215.pdf
- Attention is All you Need https://arxiv.org/abs/1706.03762
- https://developer.nvidia.com/blog/a-data-scientists-guide-to-gradient-descent-and-backpropagation-algorithms/
- https://learn.deeplearning.ai/chatgpt-prompt-eng/lesson/1/introduction
- https://huggingface.co/learn/nlp-course/chapter1/4?fw=pt
- https://learn.deeplearning.ai/chatgpt-prompt-eng/lesson/2/guidelines
- https://huggingface.co/blog/getting-started-with-embeddings
- https://huggingface.co/docs/transformers/main/tokenizer_summary
- https://www.oreilly.com/library/view/natural-language-processing/9781098136789/
- https://platform.openai.com/tokenizer
- https://platform.openai.com/docs/guides/gpt/chat-completions-api
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview
- https://python.langchain.com/docs/integrations/toolkits/openapi
- https://github.com/microsoftgraph/msgraph-sdk-powershell/blob/dev/openApiDocs/v1.0/Users.yml
- https://cookbook.openai.com/examples/function_calling_with_an_openapi_spec