Floki 👁️🗨️: Building an AI Agentic Workflow Engine with Dapr⚡️


After building an agent in Python from scratch, it was time to take the next step and build a framework for multi-agent collaboration while exploring the concepts behind agentic workflows. Traditional workflows often focus on well-defined, sequential steps, but agentic workflows introduce a level of adaptability, enabling agents to operate autonomously, make decisions, and react to dynamic environments. I wanted to explore efficient ways to structure these workflows while leveraging proven, production-grade technologies such as Dapr for orchestration, state management, and communication.
In this blog post, I share my journey in building an agentic workflow engine while exploring how to orchestrate autonomous agents in developer-friendly, code-first workflows using open-source solutions. Among the available workflow engines, I chose Dapr Workflows, a building block of the Dapr framework that leverages the Durable Task Framework (DTFx) for Go (durabletask-go) to enable long-running, persistent workflows with simple async/await coding constructs. I wondered: what if we could extend it to orchestrate language-model-based tasks, define multi-agent communications, and integrate human-in-the-loop processes?
Initial Workflow Engine Requirements 📝
Before jumping into implementation, I needed to define the initial core requirements for my agentic workflow engine, what capabilities it should support and how it should integrate with existing infrastructure.
- Workflows as Code 🎮: Define workflows in a familiar programming style, keeping them readable, testable, and easy to debug.
- Reliable & Secure Communication 📢: Enable secure multi-agent communication with async messaging, request-reply patterns, and event-driven workflows using standardized formats for consistency and traceability.
- State Management & Fault Tolerance 🎒: Ensure long-running workflows with persistent state, automatic retries, and robust error handling.
- Deterministic & Event-Driven Workflows 🔄: Blend structured logic with event-driven execution for predictable yet adaptive multi-agent workflows.
- Component-Based Modularity 🧱: Use swappable components for state, messaging, and infrastructure, keeping workflow logic clean.
- Observability 👀: Enable built-in logging, tracing, and monitoring to track and debug agentic task execution.
Why Dapr Workflows? 🎩
Initially, I considered using the Durable Task Framework (DTFx) directly for its ability to orchestrate fault-tolerant, long-running workflows with familiar async/await constructs. Originally a .NET-based framework, DTFx was later adapted into DTFx-Go, a lightweight, embeddable engine designed for use in sidecar architectures like dapr. This evolution not only enabled durable task orchestration but also unlocked access to Dapr’s broader ecosystem.
Dapr Workflows, builds on this by integrating state management, publish-subscribe (pub/sub), service invocation, virtual actors, observability, and more, all through standardized APIs. This enables a modular, cloud-native architecture for orchestrating secure and scalable agentic workflows, including multi-agent collaboration, LLM-based tasks, and human-in-the-loop processes. Thanks to its vendor-agnostic design, I could seamlessly switch between Redis, Kafka, or RabbitMQ for pub/sub without modifying core logic.
What is a Workflow? ⚙️
A workflow is a structured sequence of predefined steps designed to complete a task or process. Traditional workflows follow a deterministic approach, where tasks execute in a specific order based on predefined rules and conditions. These workflows are widely used in automation, business processes, and software orchestration to ensure consistency, efficiency, and reliability.
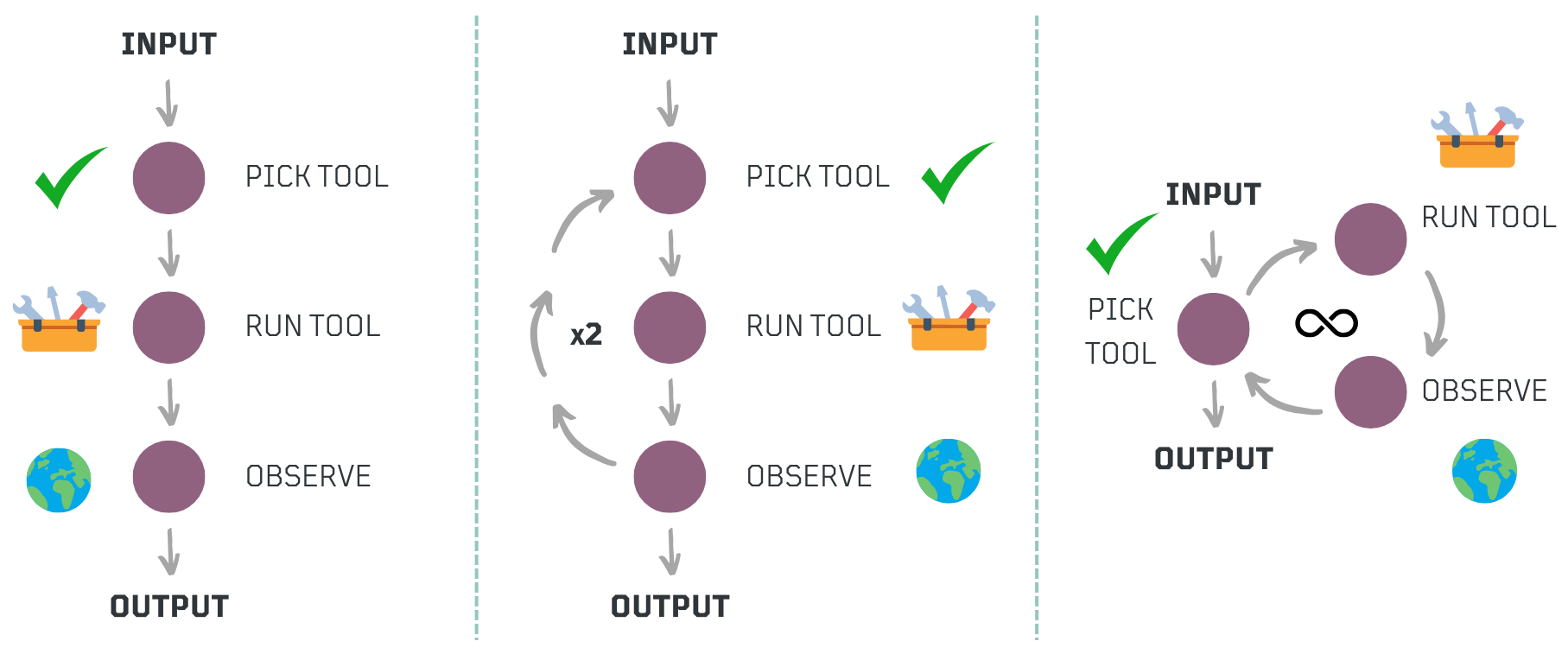
What is an Agentic Workflow? ⚙️+🤖
While workflows follow a structured sequence of predefined steps, agentic workflows extend this concept by integrating structured execution with reasoning loops, enabling adaptive decision-making. Even well-known prompting strategies like ReAct (Reason + Act) follow a structured process where an agent thinks, acts, observes, and repeats the cycle. However, what makes a workflow agentic is not just the existence of a loop but the flexibility in determining how many iterations are needed, what tools to use at each step, and when to stop.
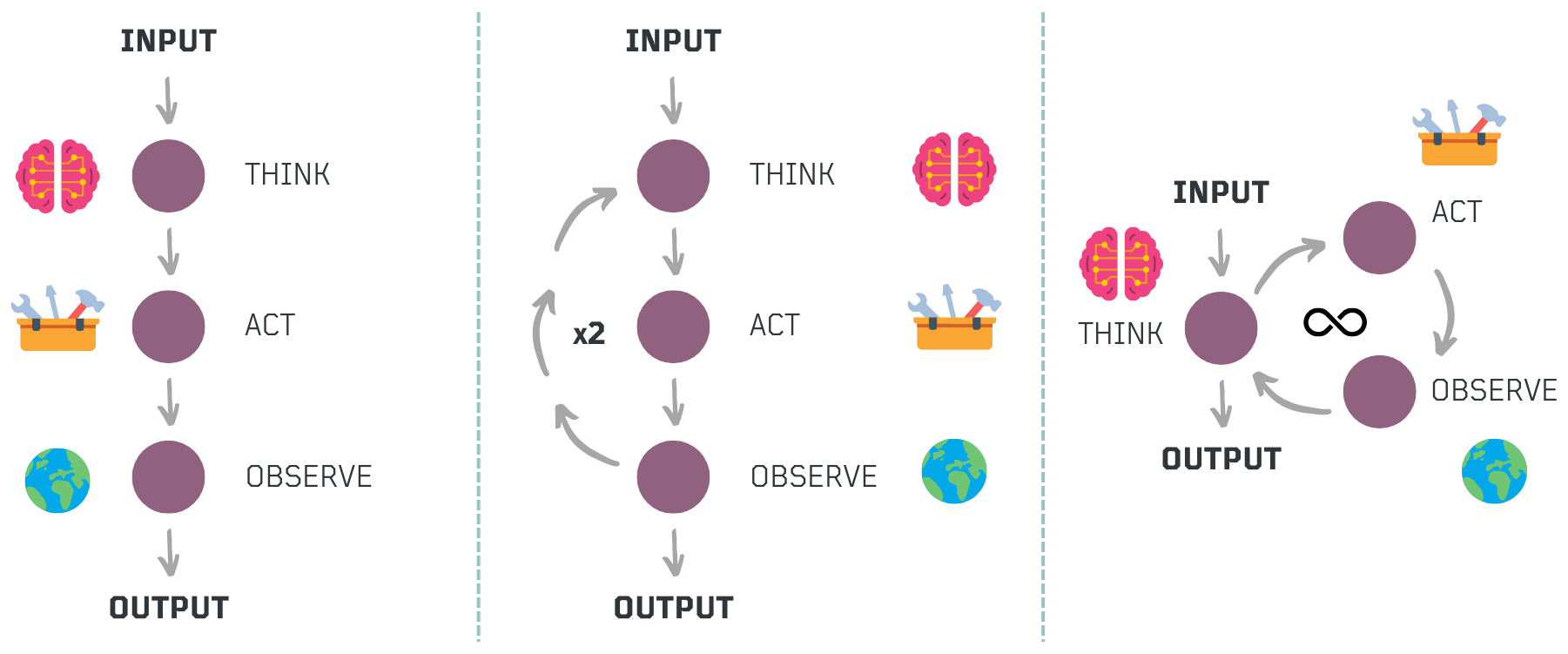
By embedding planning, feedback mechanisms, and model-driven adjustments within a structured workflow, agentic workflows bridge automation and intelligence. This allows systems to synthesize information, adjust to changing conditions, and refine actions dynamically, ensuring scalability, predictability, and resilience in complex environments.
Agentic Design Patterns 🎨
Now, the ReAct (Reason + Act) prompting strategy is just one way to structure an agent’s behavior. At its core, ReAct follows a tool-use pattern, where an agent reasons about a problem, selects the appropriate tool for the task, acts, observes the result, and iterates based on the updated context. The chosen tool can change dynamically depending on the environment and prior observations, making ReAct an adaptive approach to decision-making.
There are other agentic design patterns that serve as fundamental building blocks for different workflows. Some workflows rely on structured planning, others emphasize self-critique and improvement (Reflection), and some require multi-agent collaboration to solve complex tasks.
At a high level, four fundamental agentic design patterns emerge:
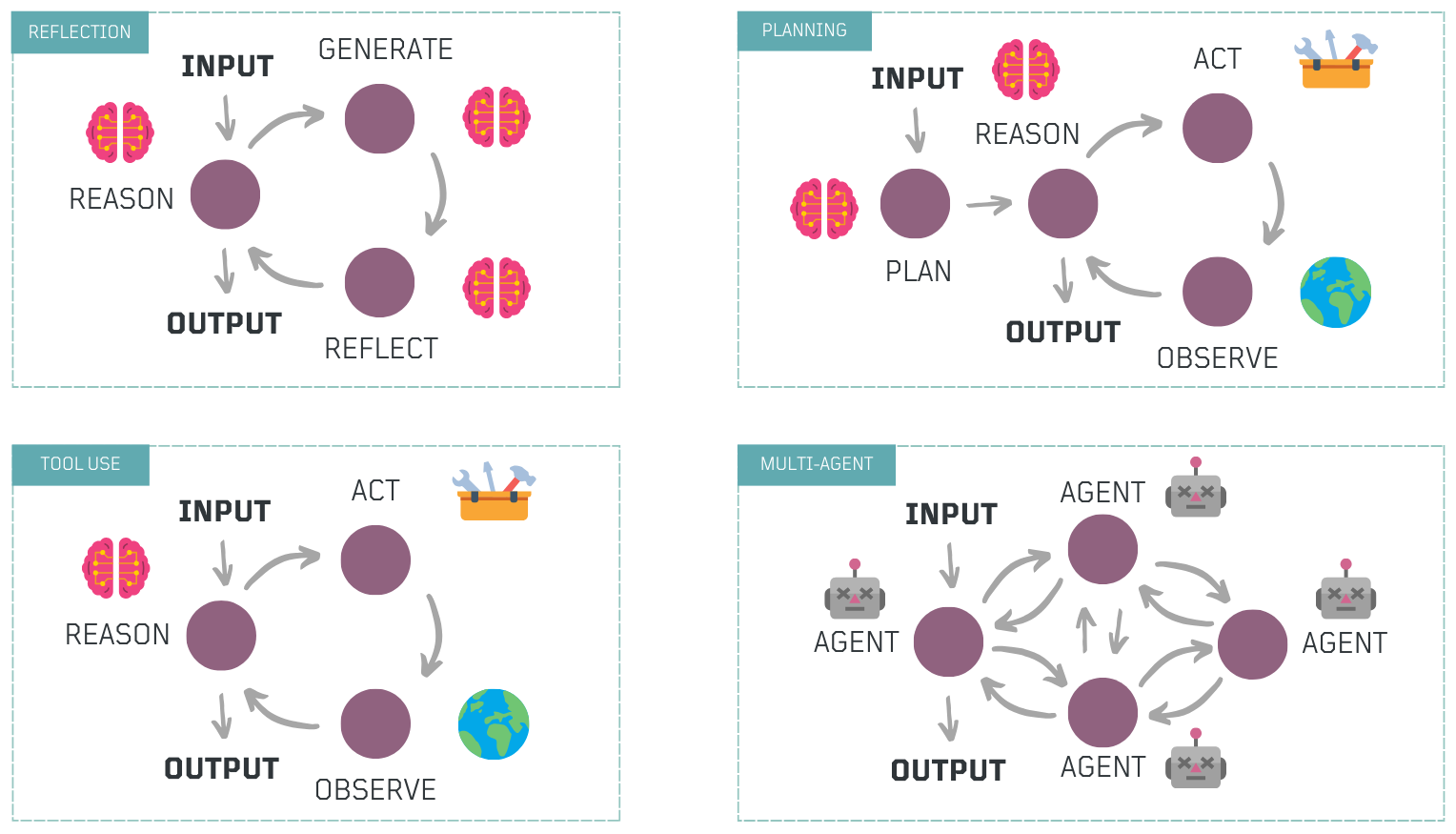
- Reflection → The agent critiques its own output, identifying errors or weaknesses and refining its responses iteratively.
- Tool Use → The agent selects and invokes external tools, such as web search or code execution, to gather information, take action, or process data.
- Planning → The agent constructs and executes structured, multi-step plans, dynamically adjusting based on intermediate results.
- Multi-Agent Collaboration → Specialized agents with distinct roles, tools, and logic work together in orchestrated workflows, enabling scalable and modular solutions.
Each of these patterns can function independently or be combined as modular components to build more advanced agentic workflows.
Fundamental Workflow Patterns 💎
While agentic design patterns define how an agent reasons, decides, and interacts with its environment, they are built on established workflow patterns that have been used in production systems for years. These patterns provide the foundation for structuring task execution, coordinating processes, and handling state.
Dapr Workflows already supports several core workflow patterns that serve as the building blocks for agentic workflows:
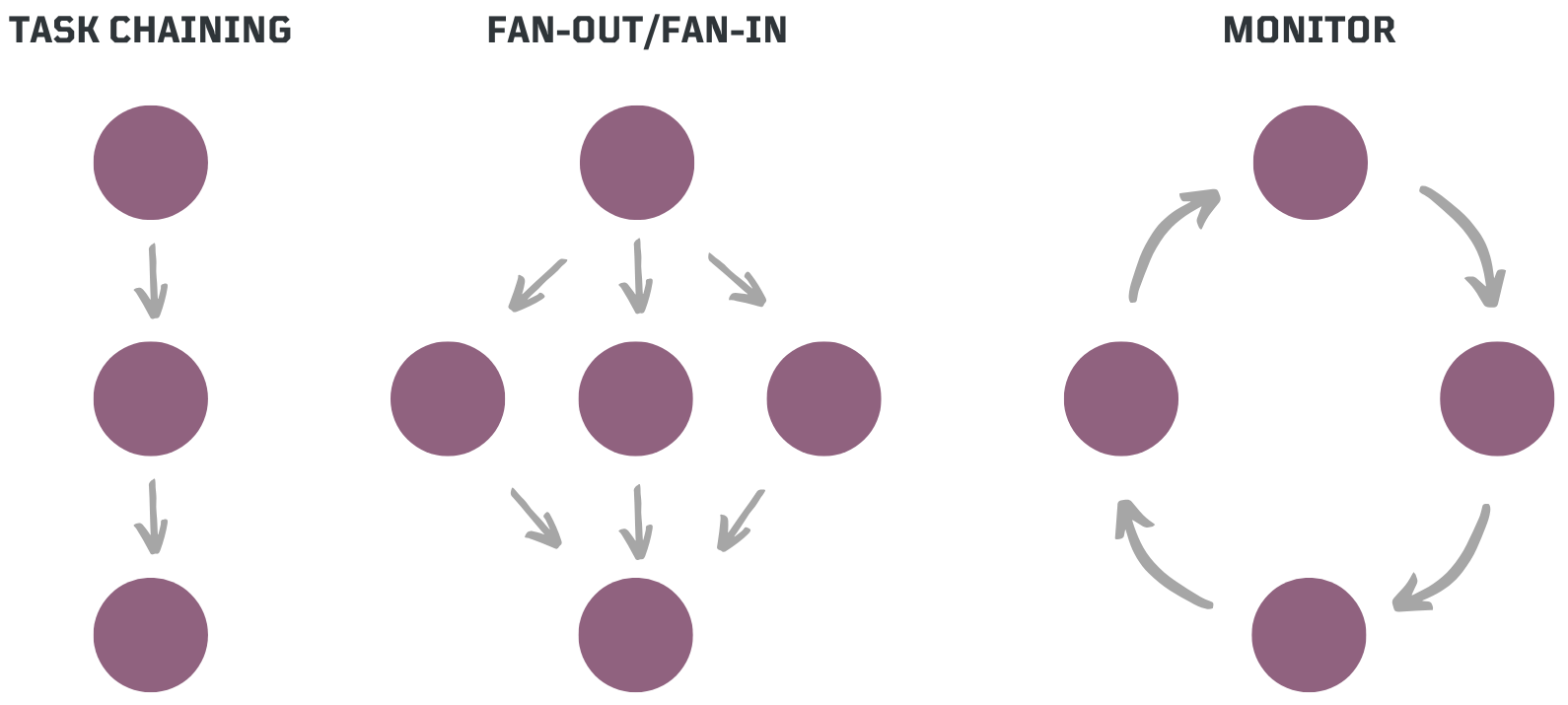
- Task Chaining 🔗 → A sequence of dependent tasks, where the output of one step serves as the input for the next, ensuring structured execution flows.
- Fan Out/Fan-In ⚡ → Parallel execution of multiple tasks followed by an aggregation phase, optimizing efficiency for large-scale processing.
- Monitor Loop 🔄 → A recurring process that continuously checks conditions, takes corrective actions, and adjusts over time.
LM-based Workflow Patterns ⚙️ + 🧠
Now, imagine extending traditional workflow patterns by embedding language models at each step. Instead of simply executing predefined tasks, workflows can use small and large language models to interpret data, adapt dynamically, and make decisions. This can be as simple as passing outputs between steps or as advanced as having a model determine the next step, select the right tool, or assign tasks to agents. By integrating reasoning into execution, language models evolve from passive tools to active decision-makers.
LM-based Task Chaining 🔗
Task chaining is a workflow pattern where each step depends on the output of the previous step, ensuring a structured flow of execution. In LM-based workflows, this allows language models to build upon prior responses, maintain context, and perform multi-step reasoning.
📡 Define A Simple OpenAI Call
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv() # Load OPENAI_API_KEY
client = OpenAI() # Initialize OpenAI client
def call_openai(prompt: str, model: str = "gpt-4o") -> str:
"""Reusable function to call OpenAI's chat completion API."""
response = client.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
model=model,
)
return response.choices[0].message.content.strip()🚀 Define a Task Chaining Workflow
Now, with Dapr Workflows, you only need to define tasks and their dependencies. The workflow runtime handles execution, state tracking, and coordination.
import dapr.ext.workflow as wf
# Initialize Workflow runtime
wfr = wf.WorkflowRuntime()
# Define Workflow logic
@wfr.workflow(name="lotr_workflow")
def task_chain_workflow(ctx: wf.DaprWorkflowContext):
character = yield ctx.call_activity(pick_character)
quote = yield ctx.call_activity(fetch_quote, input=character)
return quote
# Activity 1: Pick a random LOTR character
@wfr.activity(name="pick_character")
def pick_character(ctx):
character = call_openai("Return a random Lord of the Rings character's name.")
return character
# Activity 2: Fetch a famous quote from the selected character
@wfr.activity(name="fetch_quote")
def fetch_quote(ctx, character: str):
quote = call_openai(f"What is a famous line by {character}?")
return quote
🎩 Why Use Task Chaining with Dapr?
Isolated LM API calls in Python scripts can cause unstructured execution, redundant work, and failure handling issues. Dapr Workflows orchestrates tasks with reliability, scalability, and stateful coordination.
✅ Execution Reliability → If an API call fails (e.g., API downtime), the workflow resumes from the last successful step instead of breaking.
✅ Prevents Redundant Computation → Avoids re-running completed LM calls unnecessarily, reducing API costs and improving efficiency.
✅ Structured Orchestration → Ensures step-by-step control over LM interactions, preventing prompt drift and maintaining reasoning consistency.
✅ Built-in Retry Policies → Retries failed API requests automatically, using configurable backoff strategies to handle rate limits and transient failures.
LM-based Fan-Out/Fan-In ⚡
Fan-Out/Fan-In runs multiple tasks at the same time and combines their results before moving forward. In LM-based workflows, this enables models to generate multiple responses, aggregate them, and perform additional reasoning or processing on the combined output reducing wait time and improving efficiency.
🔀 Define a Parallel Workflow
import dapr.ext.workflow as wf
# Initialize Workflow runtime
wfr = wf.WorkflowRuntime()
# Define Workflow logic
@wfr.workflow(name="cybersecurity_slogan_workflow")
def fan_out_fan_in_workflow(ctx: wf.DaprWorkflowContext):
# Fan-out: Generate three slogans in parallel
parallel_tasks = [ctx.call_activity(generate_slogan) for _ in range(3)]
slogans = yield wf.when_all(parallel_tasks)
# Fan-in: Pass all slogans as input to let the LLM pick the best one
best_slogan = yield ctx.call_activity(select_best_slogan, input=slogans)
return best_slogan
# Activity 1: Generate a marketing slogan
@wfr.activity(name="generate_slogan")
def generate_slogan(ctx):
prompt = """Create a compelling marketing slogan for a cybersecurity company.
Keep it concise, impactful, and professional."""
slogan = call_openai(prompt)
return slogan
# Activity 2: Select the best slogan using an LLM
@wfr.activity(name="select_best_slogan")
def select_best_slogan(ctx, slogans: list):
prompt = f"""Here are three cybersecurity slogans:
{chr(10).join(slogans)}
Pick the most effective one."""
best_slogan = call_openai(prompt)
return best_slogan🎩 Why Use Fan-Out/Fan-In with Dapr?
Coordinating multiple LM tasks in parallel can be complex, requiring careful handling of execution, aggregation, and failure recovery. Dapr Workflows automates this process, ensuring efficient task distribution and synchronization.
✅ Faster Execution → Multiple LM calls run in parallel, significantly reducing total response time compared to sequential execution.
✅ Scalability → Tasks can be dynamically distributed across multiple workers, optimizing resource allocation and balancing workload.
✅ Reliable Aggregation → Ensures that all generated responses are collected, analyzed, and processed before advancing to the next stage.
✅ Fault Tolerance → If a task fails due to API errors or timeouts, it can be retried independently without affecting other parallel tasks.
LM-based Monitor 🔄
A Monitor Loop continuously checks for updates, responds to changes, and repeats as needed. In LM-based workflows, this allows a model to monitor progress, trigger actions, and determine when to stop or continue. Instead of using cron jobs or manual polling, Dapr Workflows uses the continue-as-new API to restart the workflow with updated input, keeping execution efficient.
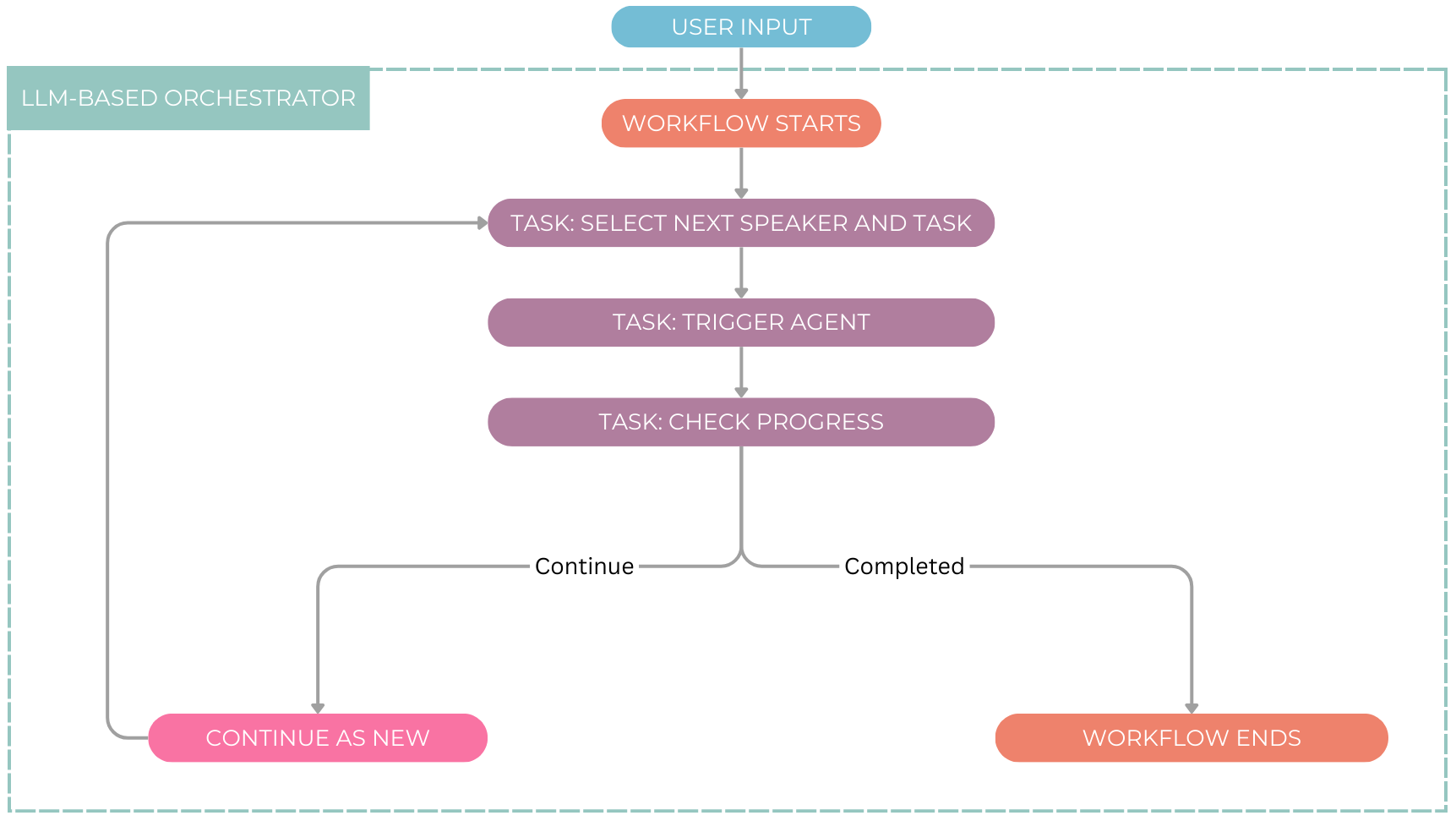
🤖 Define a Monitor Workflow
import dapr.ext.workflow as wf
from typing import Dict
# Initialize Workflow runtime
wfr = wf.WorkflowRuntime()
# Define Workflow logic
@wfr.workflow(name="agent_monitor_loop")
def monitor_loop(ctx: wf.DaprWorkflowContext, input_data: dict):
"""
An iterative LM-based workflow that selects an agent, triggers an action,
and continues monitoring until completion.
"""
iteration = input_data.get("iteration", 0)
last_response = input_data.get("last_response", "Initial request")
# Step 1: Select the next agent and task
next_agent_info = yield ctx.call_activity(select_next_agent, input=last_response)
# Step 2: Trigger the selected agent to respond
agent_response = yield ctx.call_activity(trigger_agent, input=next_agent_info)
# Step 3: Check if the task is complete
verdict = yield ctx.call_activity(check_progress, input=agent_response)
if verdict == "completed":
return agent_response # End workflow if task is done
# Step 4: Continue the workflow with updated input
ctx.continue_as_new({
"iteration": iteration + 1,
"last_response": agent_response
})
# Activity 1: Select the next agent and task
@wfr.activity(name="select_next_agent")
def select_next_agent(ctx, last_response: str) -> Dict:
""" Determines the next agent and task based on the last response. """
prompt = f"Based on this response: '{last_response}', which agent should act next and what should they do?"
return call_openai(prompt) # Expected to return a dict with "agent_name" and "agent_task"
# Activity 2: Trigger the selected agent
@wfr.activity(name="trigger_agent")
def trigger_agent(ctx, input_data: Dict):
""" Broadcasts a task to the selected agent. """
broadcast_message(input_data["agent_name"], input_data["agent_task"])
# Activity 3: Check progress
@wfr.activity(name="check_progress")
def check_progress(ctx, agent_response: str):
""" Evaluates if the workflow should continue or stop. """
prompt = f"Does the following response indicate task completion? Respond with 'completed' or 'continue':\n{agent_response}"
return call_openai(prompt)🎩 Why Use Monitor Loops with Dapr?
Dapr Workflows enables stateful, event-driven monitoring without manual polling or rigid cron jobs. Using continue-as-new, workflows restart with updated input while preserving context, preventing execution history bloat. This allows for dynamic monitoring, adapting execution intervals as needed.
✅ Adaptive Execution → Dynamically selects the next agent and task based on real-time inputs, ensuring the workflow evolves with changing conditions.
✅ Event-Driven Response → Reacts to new data, system updates, or agent actions instead of following a rigid, pre-defined sequence.
✅ Efficient Looping → Uses continue-as-new to refresh input while preserving context, preventing execution bloat and improving performance.
What About a Tool-Calling Agentic Pattern as a Dapr Workflow? 🤖 ➡️ 🧰
Let’s now put some of these concepts to the test by implementing a tool-calling agentic pattern as a Dapr Workflow. In LM-based workflows, tool execution is a critical capability that allows Autonomous agents to interact with external systems, retrieve data, or perform specific actions in the real world.
A key approach to enabling this is OpenAI’s Function Calling, introduced in June 2023. While Function Calling doesn’t execute tools directly, it allows the model to select the appropriate tool and provide structured arguments for execution. This ensures that a language model acts as a reasoning layer, determining the right tool for a given task while an execution engine runs it.
💡 How Tool Calling Works:
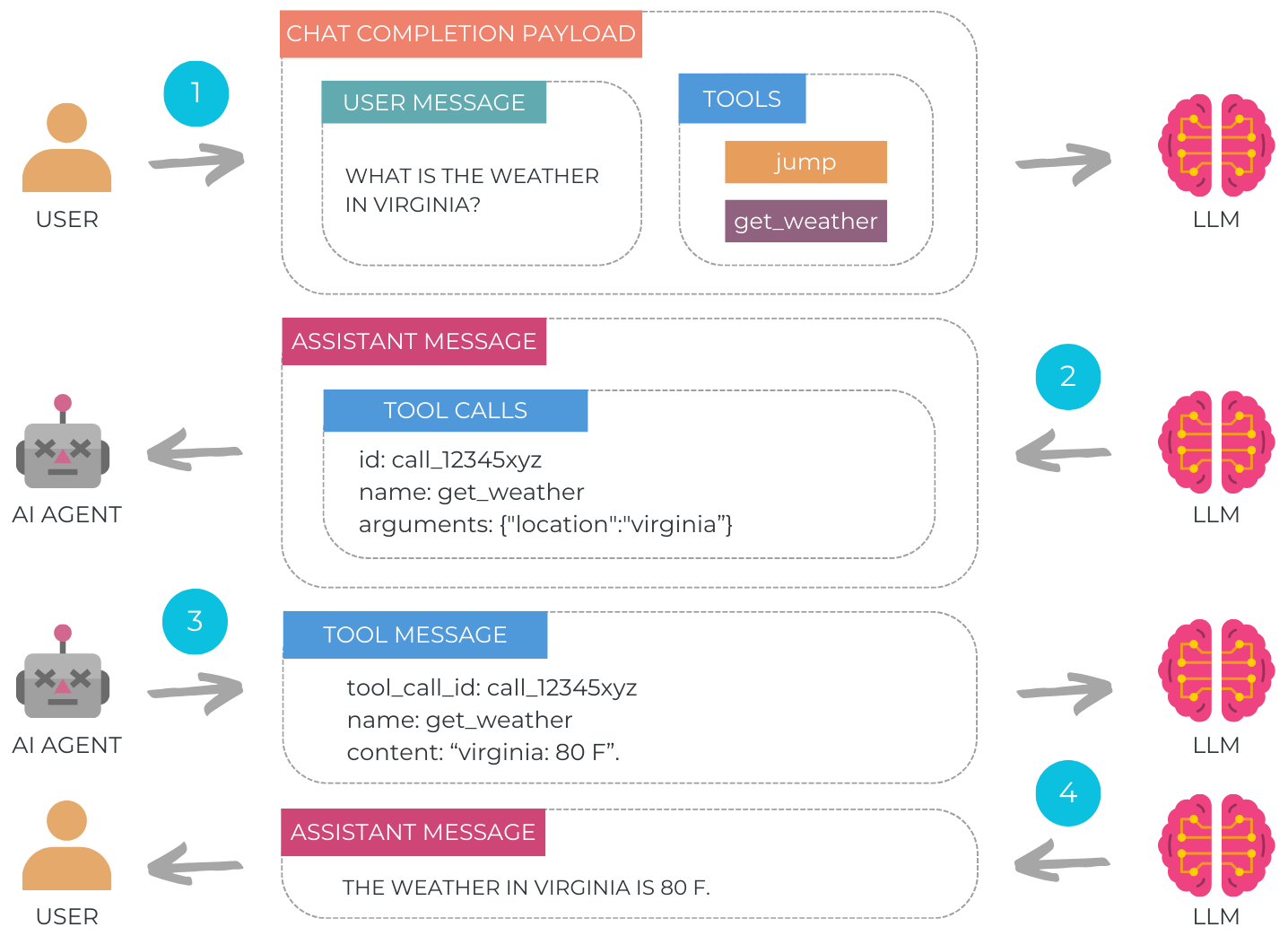
1️⃣ The user submits a task along with available tools metadata.
2️⃣ The LM selects the appropriate tool, generating structured inputs in JSON.
3️⃣ The agent parses and executes the tool using the provided arguments and sends the results back to the language model for additional processing.
4️⃣ The language model decides the next step, continuing execution or finalizing the loop providing a summary of the tool execution.
Bringing It All Together: A Multi-Pattern Workflow 🔄🔗⚡
This tool-calling workflow isn’t just a simple sequence. It combines all three core Dapr Workflow patterns:
- 🔗 Task Chaining – The tool execution depends on prior responses.
- ⚡ Fan-Out/Fan-In – Multiple tool calls can run in parallel.
- 🔄 Monitor Loop – The workflow iterates until the process is complete.
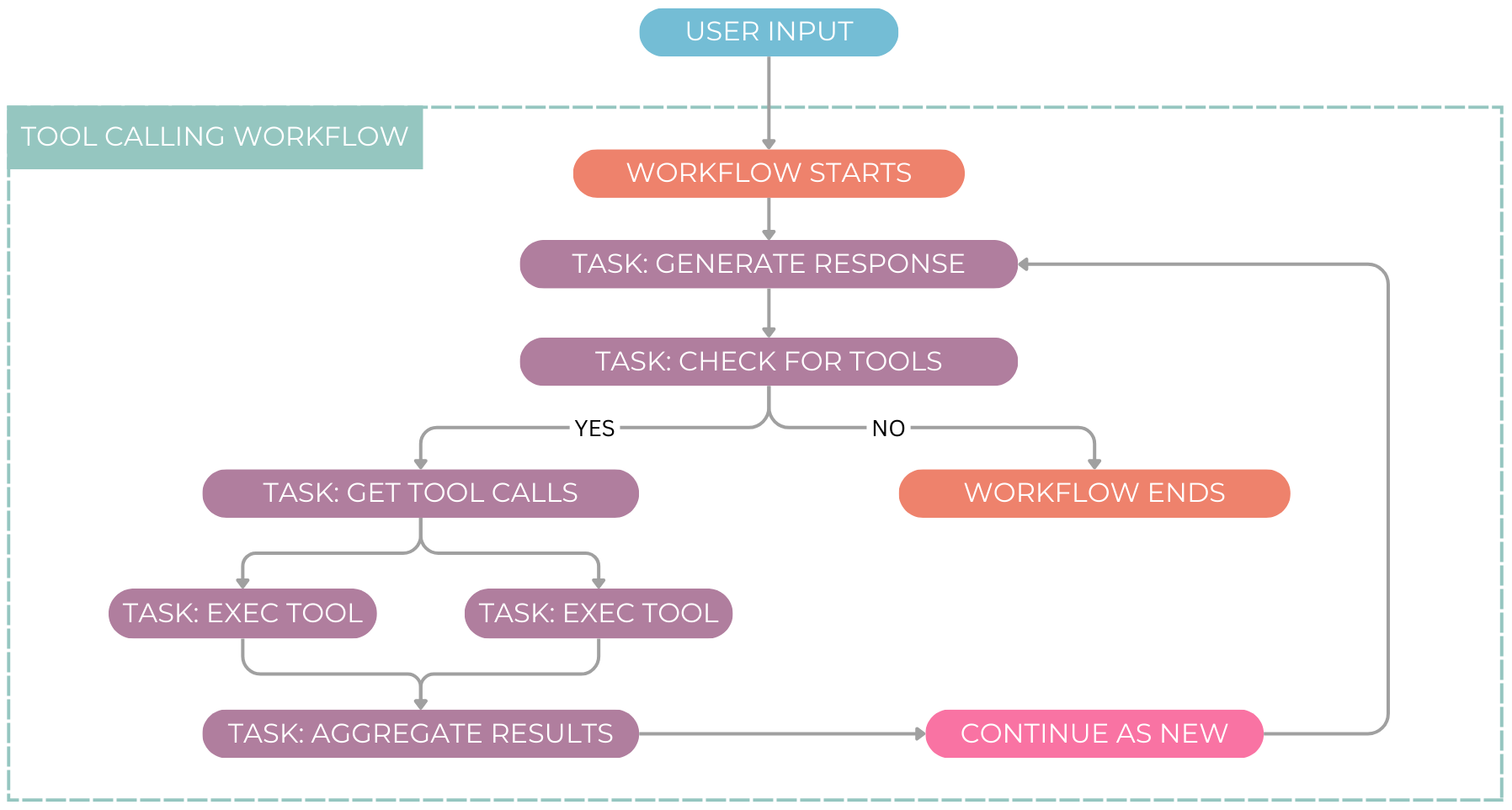
Define a Tool-Calling Workflow in Dapr 🛠️
The following implementation highlights the logical flow, demonstrating how an LM-driven agent selects and executes tools dynamically.
import dapr.ext.workflow as wf
from typing import Dict, List
# Initialize Workflow runtime
wfr = wf.WorkflowRuntime()
# Define Workflow logic
@wfr.workflow(name="tool_calling_workflow")
def tool_calling_workflow(ctx: wf.DaprWorkflowContext, input_data: Dict):
"""
A tool-calling workflow where an LLM selects, executes, and iterates over tool calls dynamically.
"""
iteration = input_data.get("iteration", 0)
task = input_data.get("task", "Default task")
# Step 1: Generate response and check if tool execution is required
response = yield ctx.call_activity(generate_response, input=task)
finish_reason = yield ctx.call_activity(get_finish_reason, input=response)
if finish_reason == "tool_calls":
tool_calls = yield ctx.call_activity(get_tool_calls, input=response)
# Step 2: Execute tools in parallel
parallel_tasks = [
ctx.call_activity(execute_tool, input=tool_call) for tool_call in tool_calls
]
tool_results = yield wf.when_all(parallel_tasks)
# Step 3: Aggregate results and generate a final response
response = yield ctx.call_activity(finalize_response, input=tool_results)
# Step 4: Determine if workflow should continue
if finish_reason == "stop" or iteration >= 5: # Set max iterations to 5 for control
return response
# Step 5: Continue workflow execution
ctx.continue_as_new({"iteration": iteration + 1, "task": response})
# Activity 1: Generate LLM Response
@wfr.activity(name="generate_response")
def generate_response(ctx, task: str):
""" Generates a response based on the task input. """
return call_openai(task)
# Activity 2: Extract Finish Reason
@wfr.activity(name="get_finish_reason")
def get_finish_reason(ctx, response: str):
""" Determines if the response requires tool execution or is final. """
return "tool_calls" if "tool_calls" in response else "stop"
# Activity 3: Extract Tool Calls
@wfr.activity(name="get_tool_calls")
def get_tool_calls(ctx, response: str) -> List[Dict]:
""" Extracts tool call information from the LLM response. """
return [{"tool": "example_tool", "args": "some_input"}]
# Activity 4: Execute Tools in Parallel
@wfr.activity(name="execute_tool")
def execute_tool(ctx, tool_call: Dict):
""" Executes a tool call with the provided arguments. """
return f"Executed {tool_call['tool']} with {tool_call['args']}"
# Activity 5: Aggregate Results
@wfr.activity(name="aggregate_results")
def aggregate_results(ctx, tool_results: List[str]):
""" Aggregates tool execution results and formulates a response. """
return f"Tool execution completed: {', '.join(tool_results)}"So far, we’ve defined 2 powerful agentic patterns using Dapr Workflows:
- An Orchestrator 🤖: Selects the next speaker, sends a message, processes responses, and decides whether to continue or stop.
- A Tool-Calling Agent 🧰: Receives a task, determines if a tool is needed, executes one or more tools in parallel if required, or simply responds directly.
What if we extend this approach to multiple agents, each with specialized tools, roles, and responsibilities? Instead of a single agent handling all tasks, multiple agents could collaborate within a structured workflow, each contributing their expertise. But how do they exchange information and coordinate their actions?
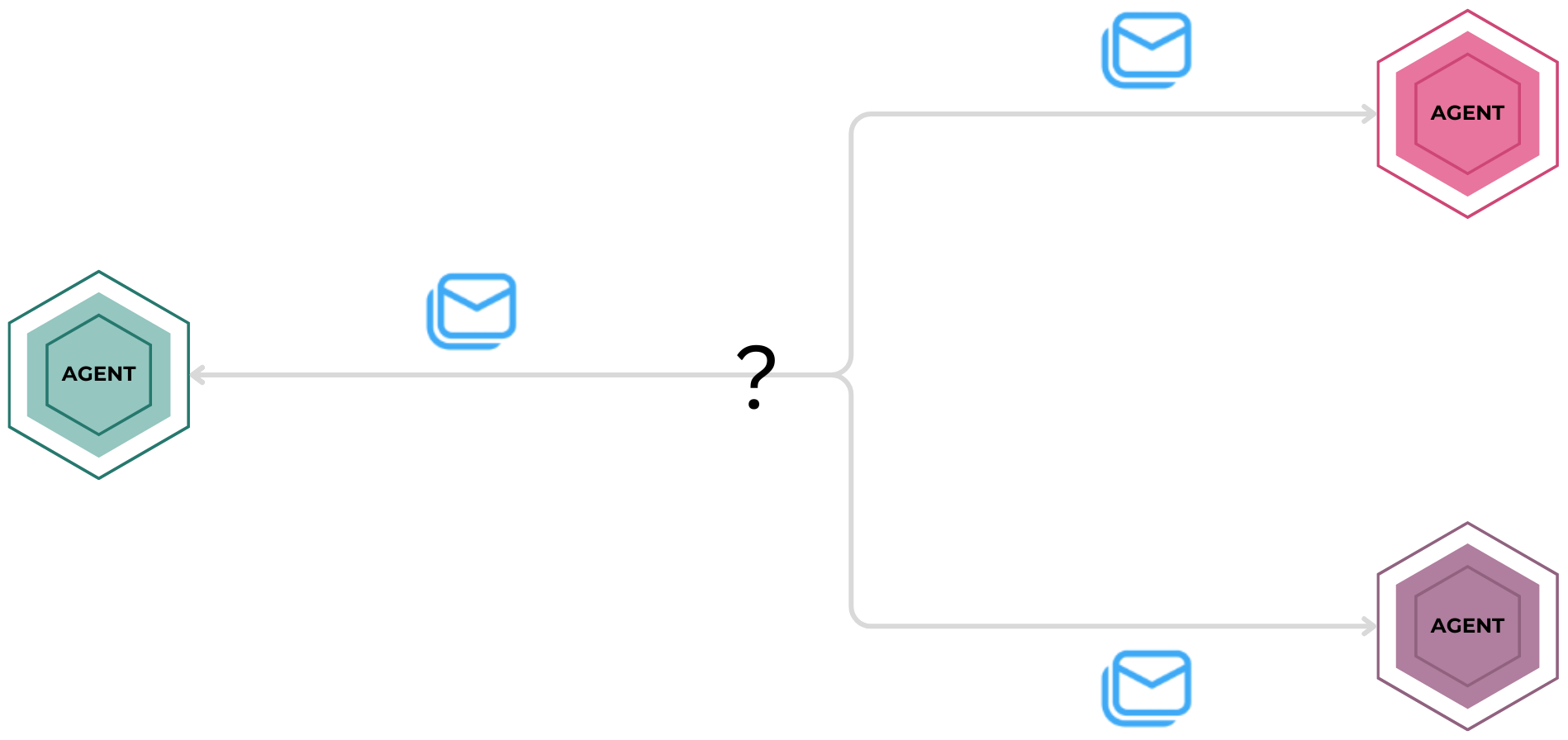
Orchestrating Tasks Alone Isn’t Enough 🚀
When defining agentic workflows with Dapr, each workflow runs alongside its own Dapr sidecar, exposing a suite of powerful APIs beyond just orchestration. Unlike traditional task orchestration frameworks, Dapr workflows aren’t isolated and they can seamlessly integrate with messaging, state management, and external services to create fully connected systems.
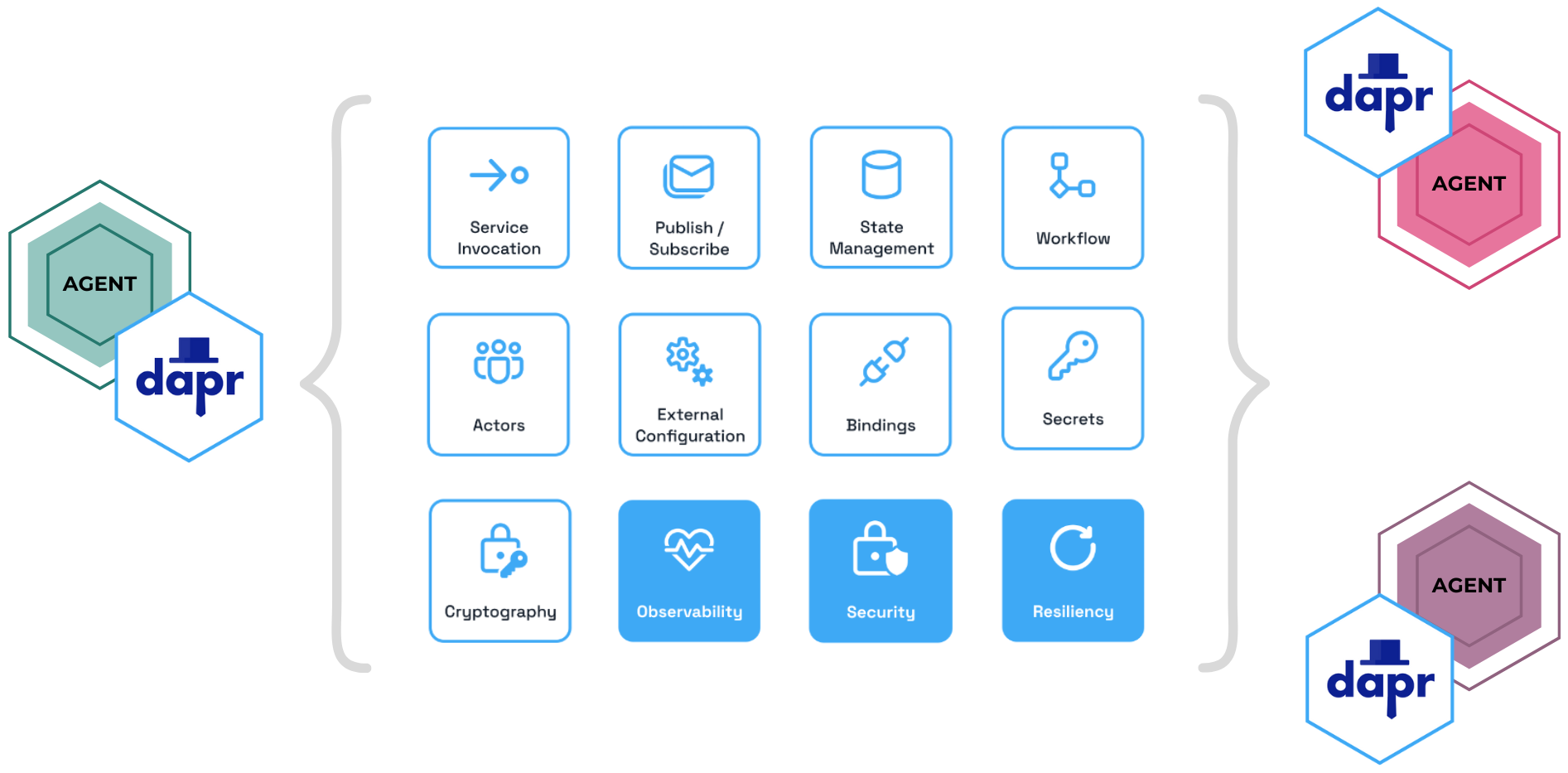
Enabling Agent Communication with Dapr’s Pub/Sub API 📬
Did you know that agents can communicate using Dapr’s Pub/Sub API?. This system allows agents to send and receive messages asynchronously, decoupling their interactions and ensuring efficient collaboration. In this model, agents act as publishers or subscribers, sending and receiving messages to and from specific topics. Topics provide the channels for communication, allowing agents to stay updated and handle differnt types of messages.
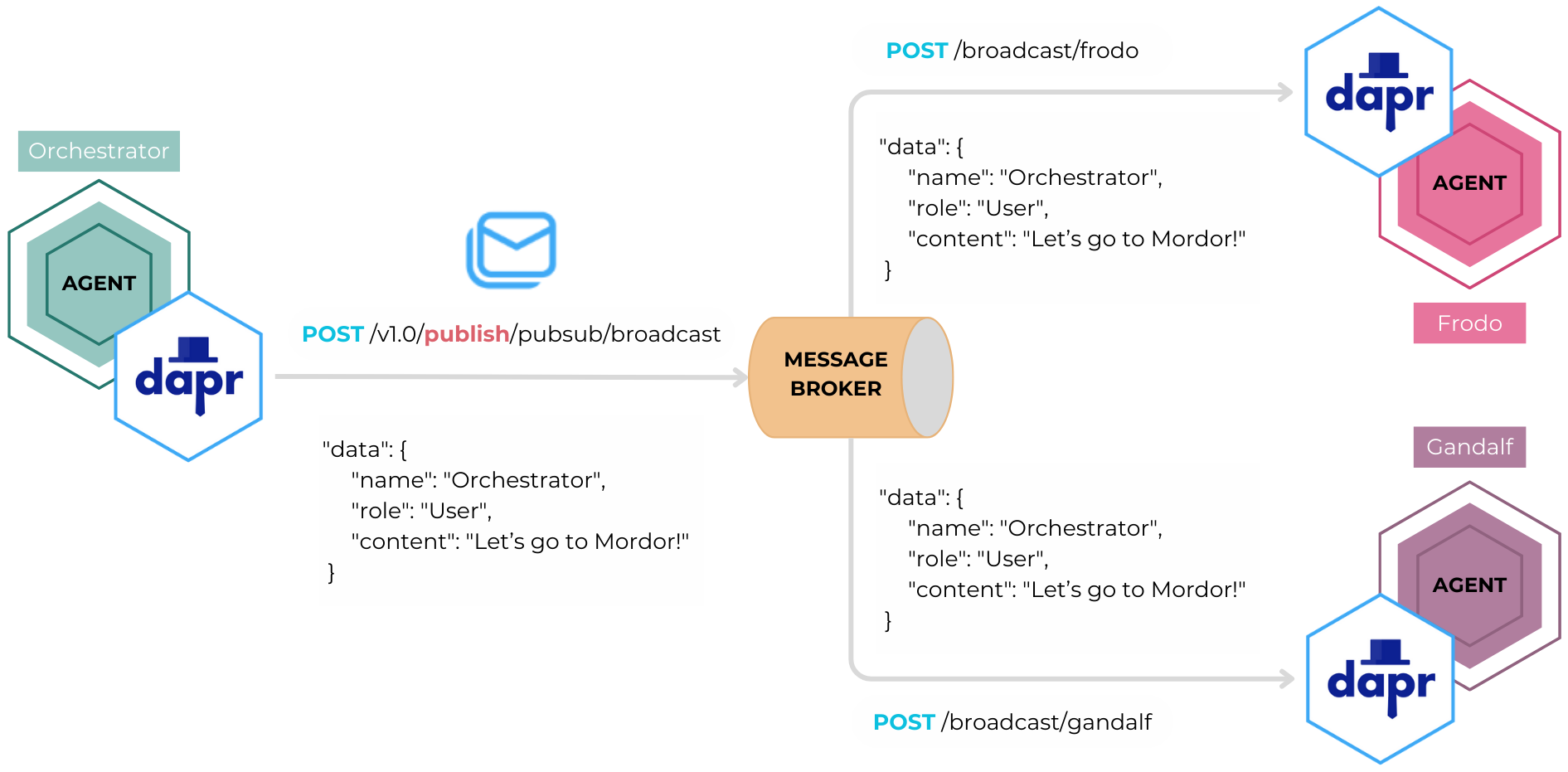
Enabling the Dapr FastAPI Extension
To achieve this, we can leverage the Dapr Python SDK integration with FastAPI using the dapr-ext-fastapi extension. This integration makes it simple to subscribe to topics and handle events, whether they’re specific to a particular agent or broadcast to all agents. In the example below, an agent subscribes to both a task-specific topic and a broadcast topic, enabling it to process individual requests to process a task while staying synchronized with the broader system.
import uvicorn
from fastapi import Body, FastAPI
from dapr.ext.fastapi import DaprApp
# Define the FastAPI application
app = FastAPI()
# Initialize the Dapr app with FastAPI
dapr_app = DaprApp(app)
# Define a handler for an agent-specific event
@dapr_app.subscribe(pubsub='pubsub', topic='agent_name_topic')
def handle_agent_event(event_data: Body()):
"""
Handles events specific to this agent. For example, a task or message sent directly to this agent.
"""
# Process the event data here
# Example: if the event has a task, execute it
# Execute task or update internal state
# Define a handler for the broadcast event
@dapr_app.subscribe(pubsub='pubsub', topic='broadcast_topic')
def handle_broadcast_event(event_data: Body()):
"""
Handles broadcast messages sent to all agents.
Broadcasts are messages that are intended for all subscribed agents.
"""
# Process the broadcast event here
# Example: log the broadcast, notify the agent, or update shared state
# Run the FastAPI app with Dapr integration
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=30212)
Enabling CloudEvents and Message Routing
With Dapr integrated into FastAPI and topics subscribed, we can improve our setup by adding more control over how messages are routed to specific event handlers. Dapr uses the CloudEvents 1.0 specification as its standard message format for all pub/sub messaging, providing useful features like tracing, content-type handling, and sender verification. CloudEvents wraps messages with additional context, such as event type, source, and payload details, making it easier to route messages based on event data without complex conditional logic.
By leveraging this structured format, we can define routing rules to route CloudEvents to the right event handlers based on attributes like the event.type or other message contents. This approach simplifies the routing logic and increases flexibility, enabling efficient communication in our system.
The message_router Decorator
To implement this, we can create a message_router decorator that defines routing rules and assigns them to event handlers based on CloudEvents data. This modular method makes our system more scalable, allowing us to easily add new event types and handlers. This is ideal for our AI agentic workflow engine, where different agents need to handle diverse events efficiently.
from fastapi import Body
from dapr.ext.fastapi import DaprApp
from typing import Optional
# External function to add a subscription and routes with rules dynamically
def add_subscription_and_routes(pubsub_name: str, topic_name: str, rules: list, dead_letter_topic: str = None):
"""
Adds a new subscription and routing rules to the internal subscriptions.
"""
subscription = {
"pubsubname": pubsub_name,
"topic": topic_name,
"routes": {"rules": rules},
**({"deadLetterTopic": dead_letter_topic} if dead_letter_topic else {}),
}
dapr_app._subscriptions.append(subscription)
# Function to create a route dynamically with the given rules
def message_router(pubsub_name: str, topic_name: str, rules: list, route: Optional[str] = None, dead_letter_topic: Optional[str] = None):
def decorator(func):
# Dynamically register the route
event_handler_route = f'/events/{pubsub_name}/{topic_name}' if route is None else route
# Register the route to the FastAPI app
dapr_app._app.add_api_route(
event_handler_route, func, methods=["POST"], tags=["PubSub"]
)
# Add subscription and rules
add_subscription_and_routes(pubsub_name, topic_name, rules, dead_letter_topic)
return func
return decoratorRewriting Subscriptions Using CloudEvents
import uvicorn
from fastapi import FastAPI
from dapr.ext.fastapi import DaprApp
# Define the FastAPI application
app = FastAPI()
# Initialize the Dapr app with FastAPI
dapr_app = DaprApp(app)
# Define event handlers with dynamic routing
@message_router(
pubsub_name='messagepubsub',
topic_name='broadcast_topic',
rules=[{"match": 'event.type == "BroadcastMessage"', "path": "/events/messagepubsub/beacon_channel/handle_broadcast_event"}]
)
async def handle_broadcast_event(event_data: Body()):
"""
Handles broadcast messages sent to all agents.
Broadcasts are messages that are intended for all subscribed agents.
"""
# Process the broadcast event here
# Example: log the broadcast, notify the agent, or update shared state
@message_router(
pubsub_name='messagepubsub',
topic_name='agent_name_topic',
rules=[{"match": 'event.type == "TriggerAction"', "path": "/events/messagepubsub/agentname/handle_agent_event"}]
)
async def handle_agent_event(event_data: Body()):
"""
Handles events specific to this agent. For example, a task or message sent directly to this agent.
"""
# Process the event data here
# Example: if the event has a task, execute it
# Execute task or update internal state
# Run the FastAPI app with Dapr integration
if __name__ == "__main__":
uvicorn.run(dapr_app._app, host="0.0.0.0", port=30212)What about Component-Based Modularity? 🤔
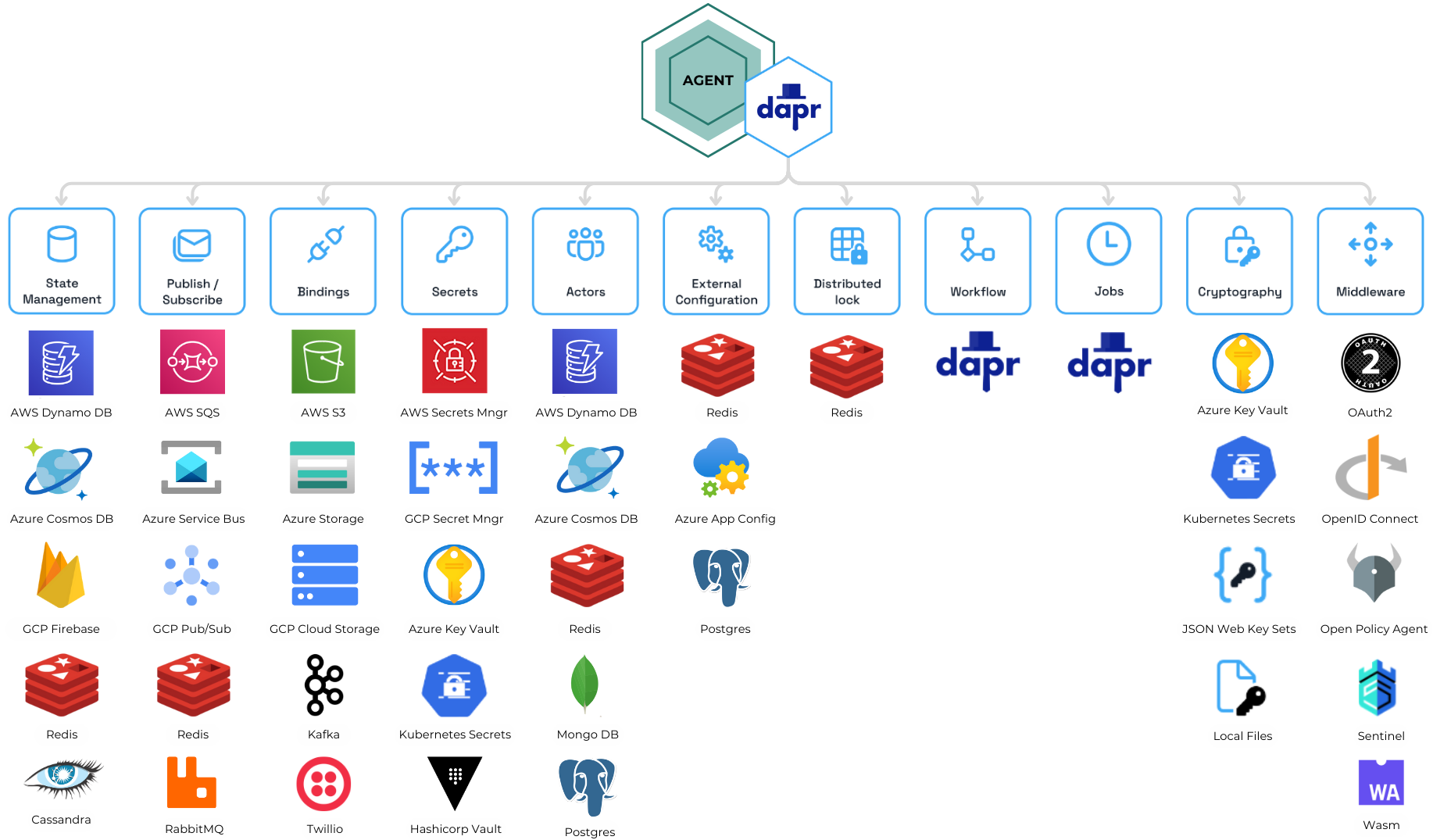
With our system now handling durable workflows with persistent state and CloudEvents-based messaging, the next step was to review the "swappable components" requirement. This concept allows agents to easily switch between different technologies for state management, messaging, and more, while keeping the workflow logic intact. By using Dapr, agents can interact with components like Redis or Kafka for messaging and state management, ensuring flexibility and easy integration with different environments.
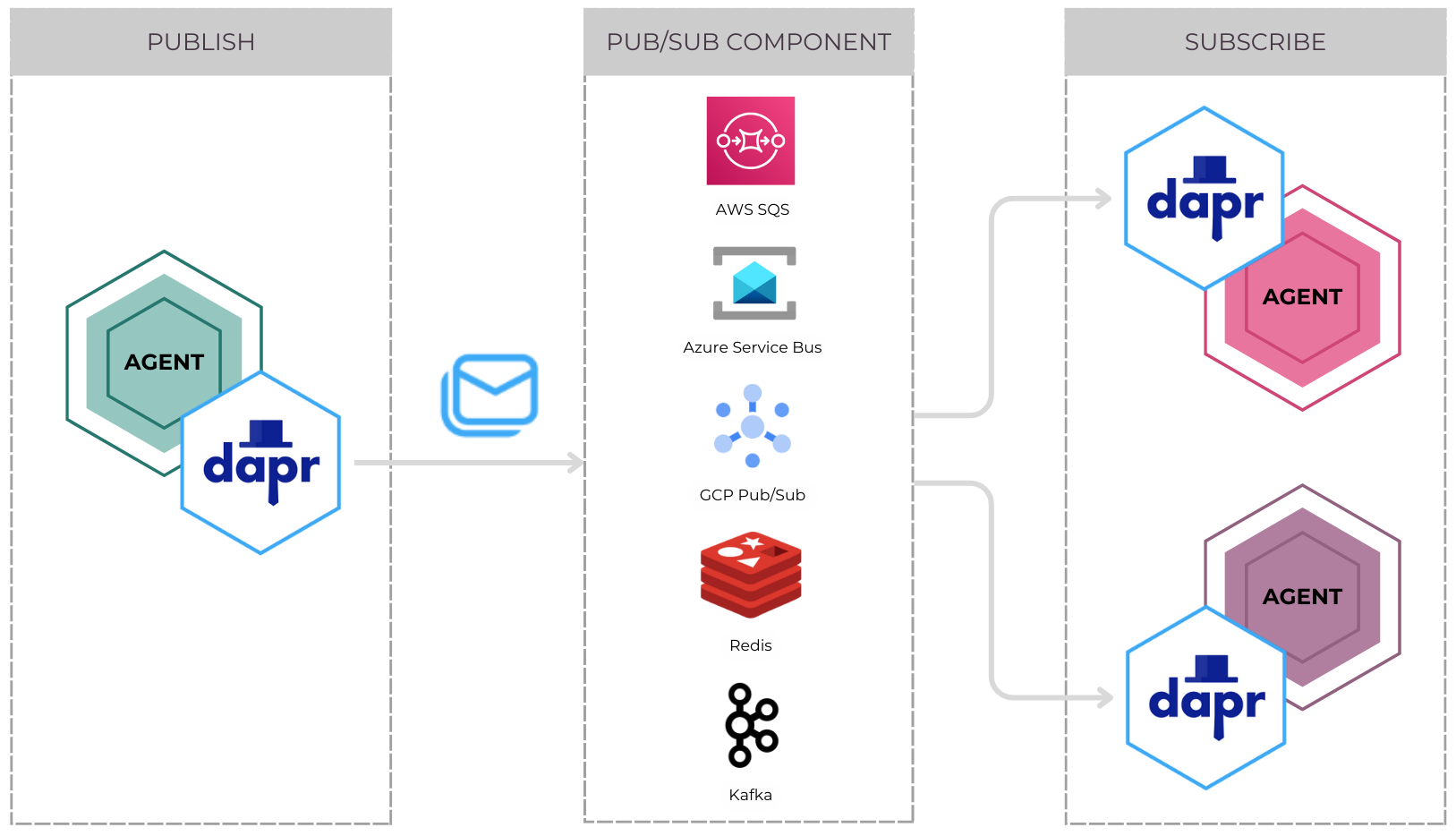
So, if you think about our previous messaging system, it would look like this:
State Management: Built-in State and Agent-Specific Data ⚙️🤖📝
One thing I was curious about when diving into all these components was the concept of state in Dapr workflows. Was it referring to the built-in state for running durable tasks, like persistence, retries, and task execution, or is it the state of the agentic system such as chat history and task completion? While Dapr workflows handle durable state for long-running tasks, the agentic system needed to track agent-specific data, ensuring smooth communication and synchronization across the team. I needed to learn more about these two types of state.
Built-in State Management
Dapr leverages built-in state management for workflows, providing a durable, fault-tolerant foundation for long-running tasks. As workflows are executed, their state is continuously saved to a state store, and actors ensure that tasks are retried automatically in case of failure. This enables seamless execution and ensures that tasks and workflows are preserved across restarts and system crashes.
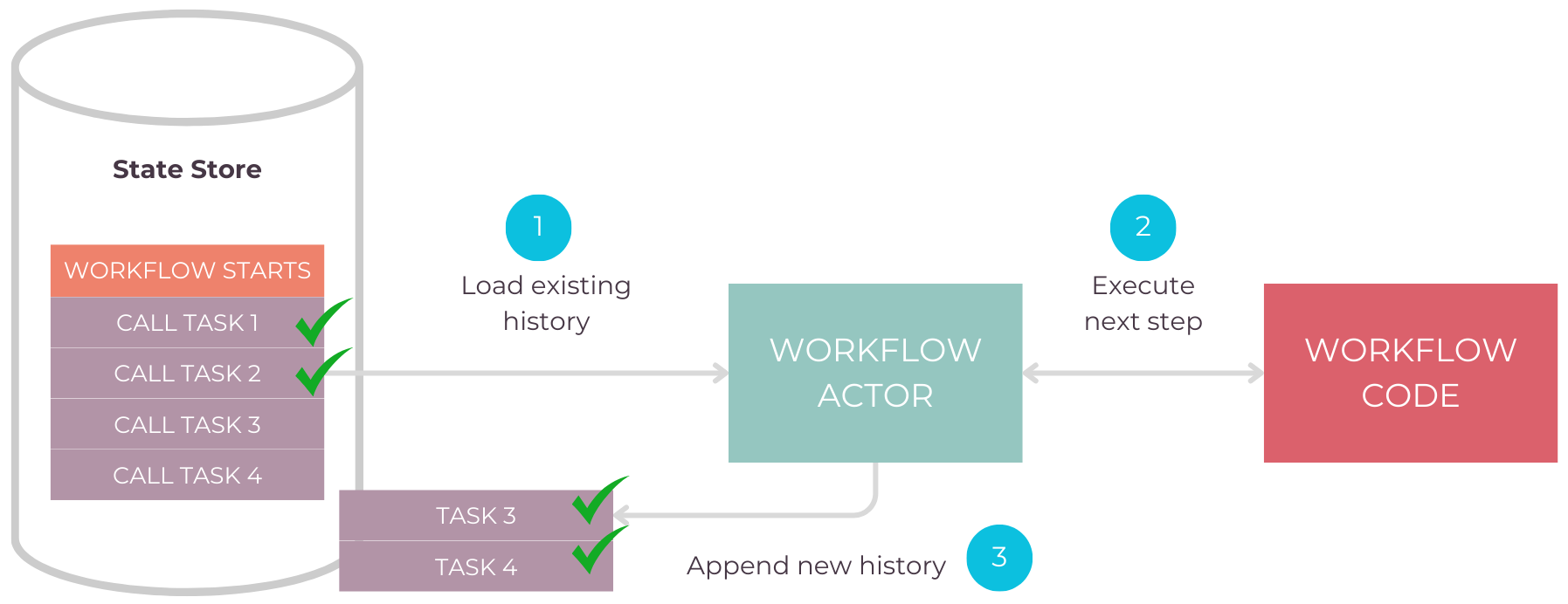
Agentic System State
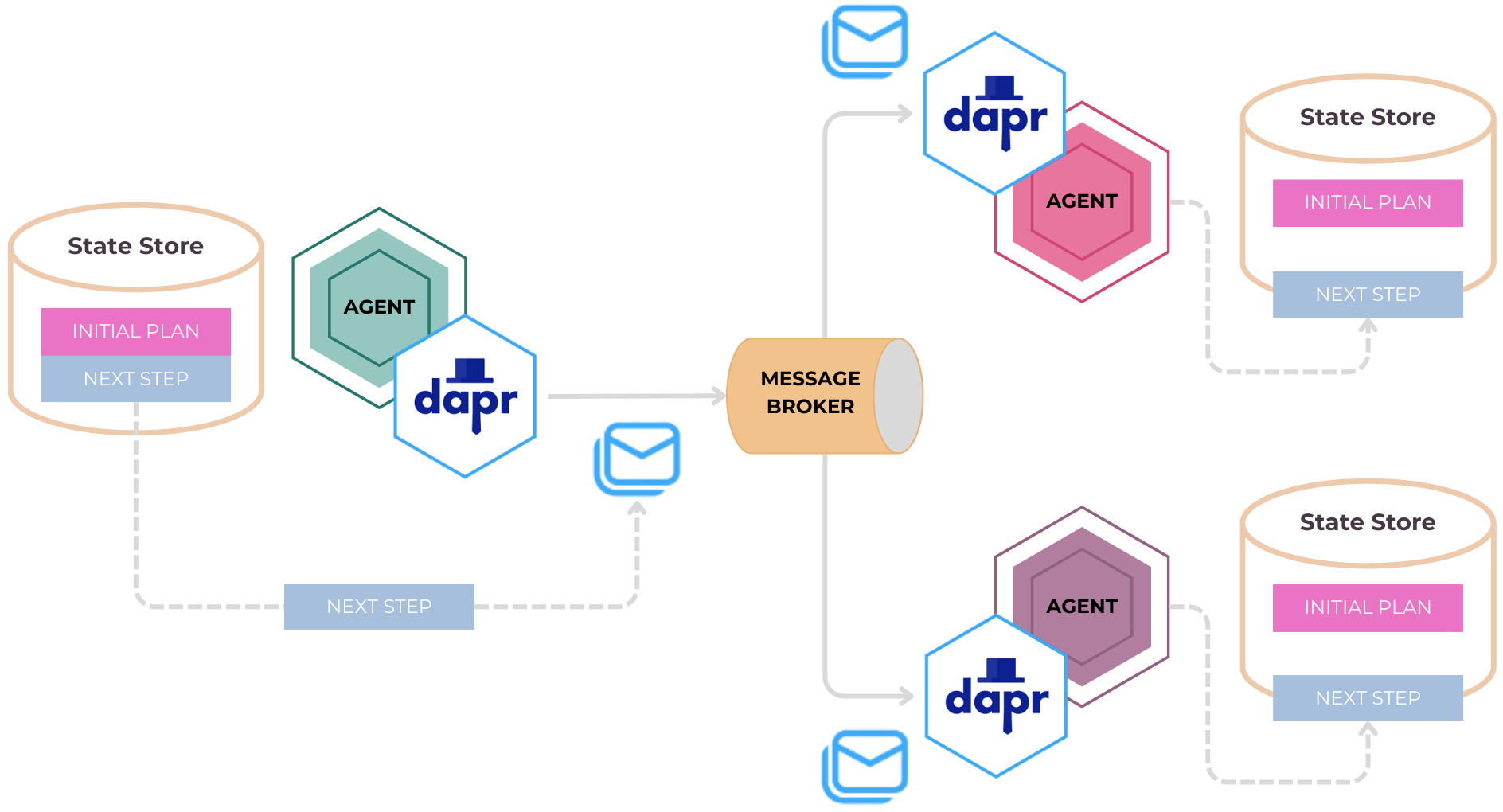
For an agentic system, managing state goes beyond just keeping track of tasks or workflows. In this system, agents maintain their own state such as chat history, task completion status, and plans while synchronizing their actions with others in a team. This means that, just like workflows, agents can track their progress and context across interactions. For example, while executing tasks or orchestrating workflows, agents can keep their message history in sync with other agents.
Enabling Tracing on Agentic Workflows 📊🔍
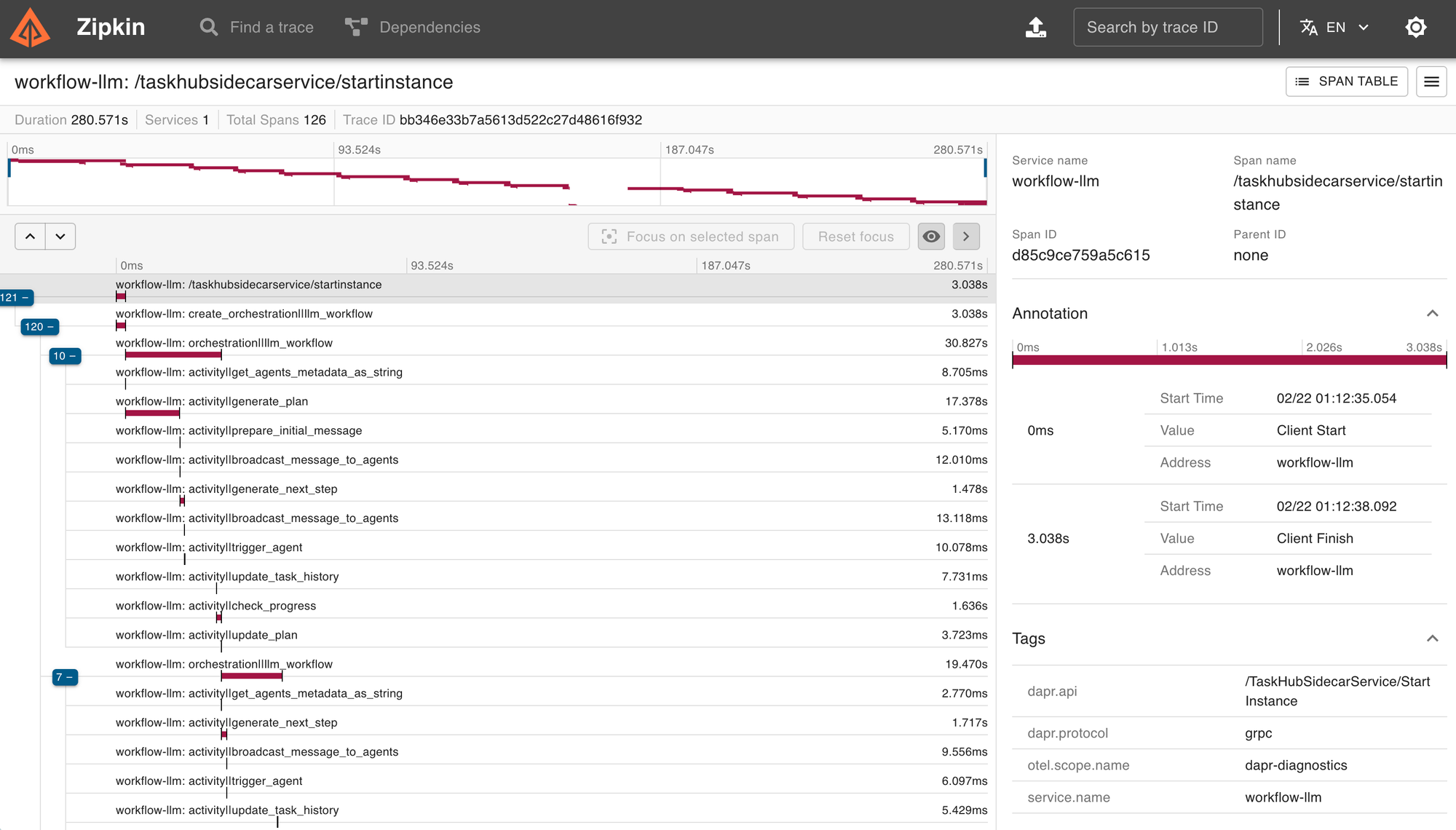
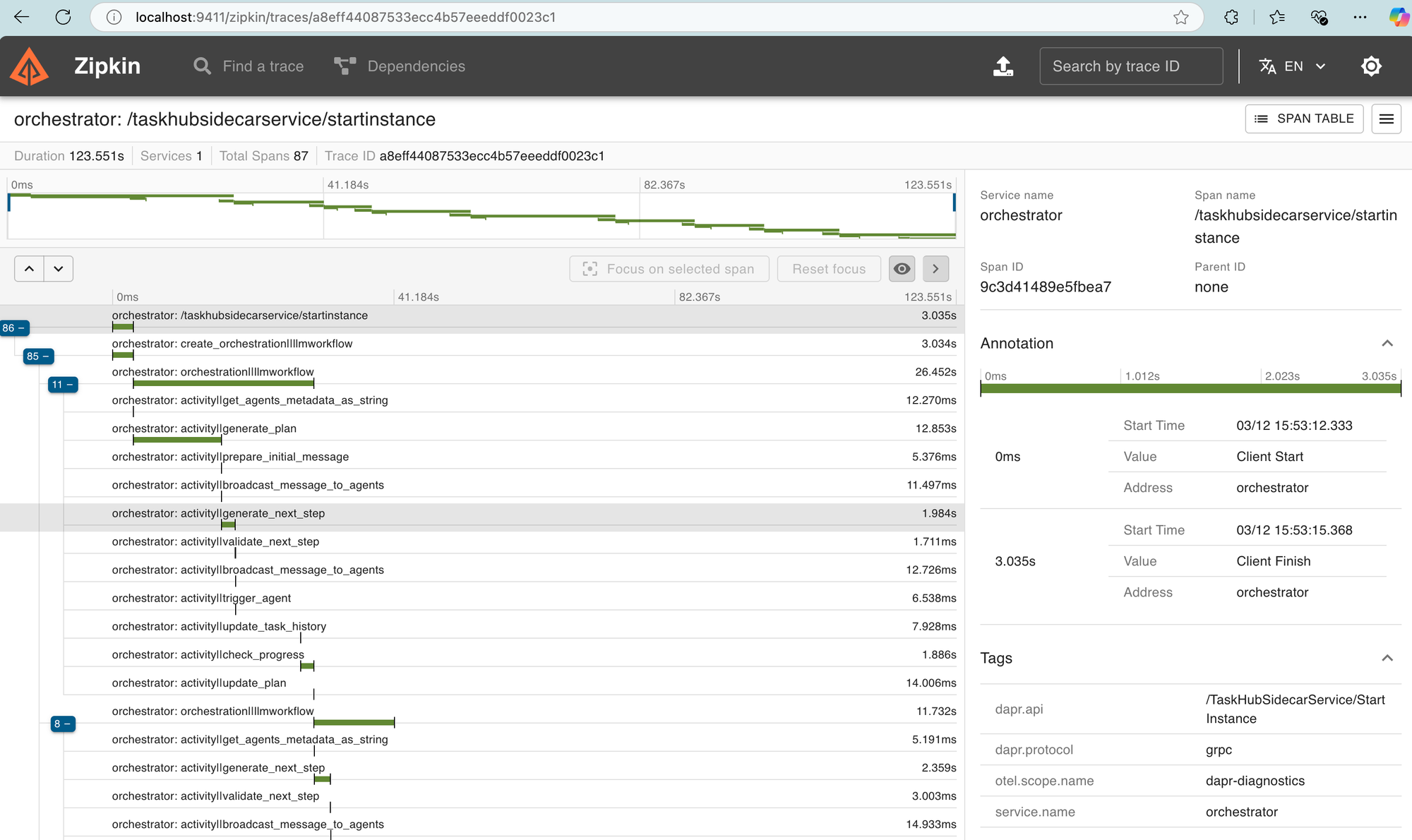
Finally, I started wondering, "How do I trace and gather telemetry from my agentic workflows?" It was a game-changer when I realized that Dapr offers built-in telemetry for workflows right out of the box. I was amazed to learn that with Dapr's use of Open Telemetry (OTEL) and the W3C tracing specification, task execution is tracked seamlessly across microservices 🔥. This means that tracing is automatically handled for me, without needing to write complex instrumentation code. This built-in feature allows me to monitor task starts, completions, retries, and failures effortlessly. While I’m not yet capturing AI inference calls, the ability to track durable tasks and workflow execution was already a huge benefit. Many other frameworks don’t provide this level of observability by default, and it made the debugging and monitoring of my workflows incredibly smooth.
Remember our basic LM-based Orchestrator? A more advanced version of it would look like this in a Zipkin dashboard 🔥.
Yes, It is Possible to Build an AI Agentic Workflow Engine with Dapr! 🤖🚀
With Dapr, it was clear that all my core requirements for a flexible, modular, and fault-tolerant agentic workflow engine were met. From durable workflows with persistent state to seamless multi-agent communication and built-in observability, Dapr covered everything I needed. Its components integrated seamlessly into the architecture, offering flexibility across various technologies while ensuring efficient execution and robust error handling.
The next step was figuring out how to integrate all these components and make it easy to create agentic workflows. I needed to create a few abstractions and tie everything together, ensuring simplicity for both myself and others working with the system 🤔.
Enter Floki 👁️🗨️⚒️
Floki is an open-source framework for researchers and developers to experiment with LLM-based autonomous agents. It provides tools to create, orchestrate, and manage agents while seamlessly connecting to LLM inference APIs. Built on Dapr, Floki leverages a unified programming model that simplifies microservices and supports both deterministic workflows and event-driven interactions.
It also facilitates agent collaboration through Dapr’s Pub/Sub integration, where agents communicate via a shared message bus, simplifying the design of workflows where tasks are distributed efficiently, and agents work together to achieve shared goals. By bringing together these features, Floki provides a powerful way to explore agentic workflows and the components that enable multi-agent systems to collaborate and scale, all powered by Dapr.
Pre-Requirements
- Dapr CLI
- Python >=3.10
Installing Floki
- As a Python package using Pip
pip install floki- Remotely from GitHub
pip install git+https://github.com/Cyb3rWard0g/floki.git- From source with
poetry:
git clone https://github.com/Cyb3rWard0g/floki
cd floki
poetry installIntroducing LM-based Workflow Tasks 🧠 🎮
When defining LM-based task chaining workflows, we previously had to manually define OpenAI functions and create separate workflow activities. However, in Floki, I introduced a Task concept that simplifies this. The Task acts as a decorator around the Dapr workflow activities, bringing in LM capabilities and additional context such as descriptions and history.
Here’s how Tasks and Activities differ in Floki::
- Activities: Basic building blocks in workflows. They represent simple tasks or external services that the workflow executes. They are typically just functions that can be invoked in the workflow.
- Tasks: A more advanced abstraction built on top of activities. Tasks encapsulate additional context and features, such as descriptions that are automatically formatted into prompts for LM clients (e.g., OpenAI). This extra context makes it easy to execute complex workflows where tasks interact with language models and agents with more dynamic behavior.
Using the @task Decorator
With the new @task decorator in Floki, you can now execute LM-based task chaining workflows in a simplified manner, without manually managing every step. The decorator automates the complexity, making the process more intuitive. What's more, the familiar Python function syntax is preserved. The function parameters are automatically injected into the task's description, allowing dynamic placeholders within the prompt. This means you can define your task logic using standard Python parameters, and Floki will handle formatting them into the description/prompt for LLMs, reducing the need for manual intervention.
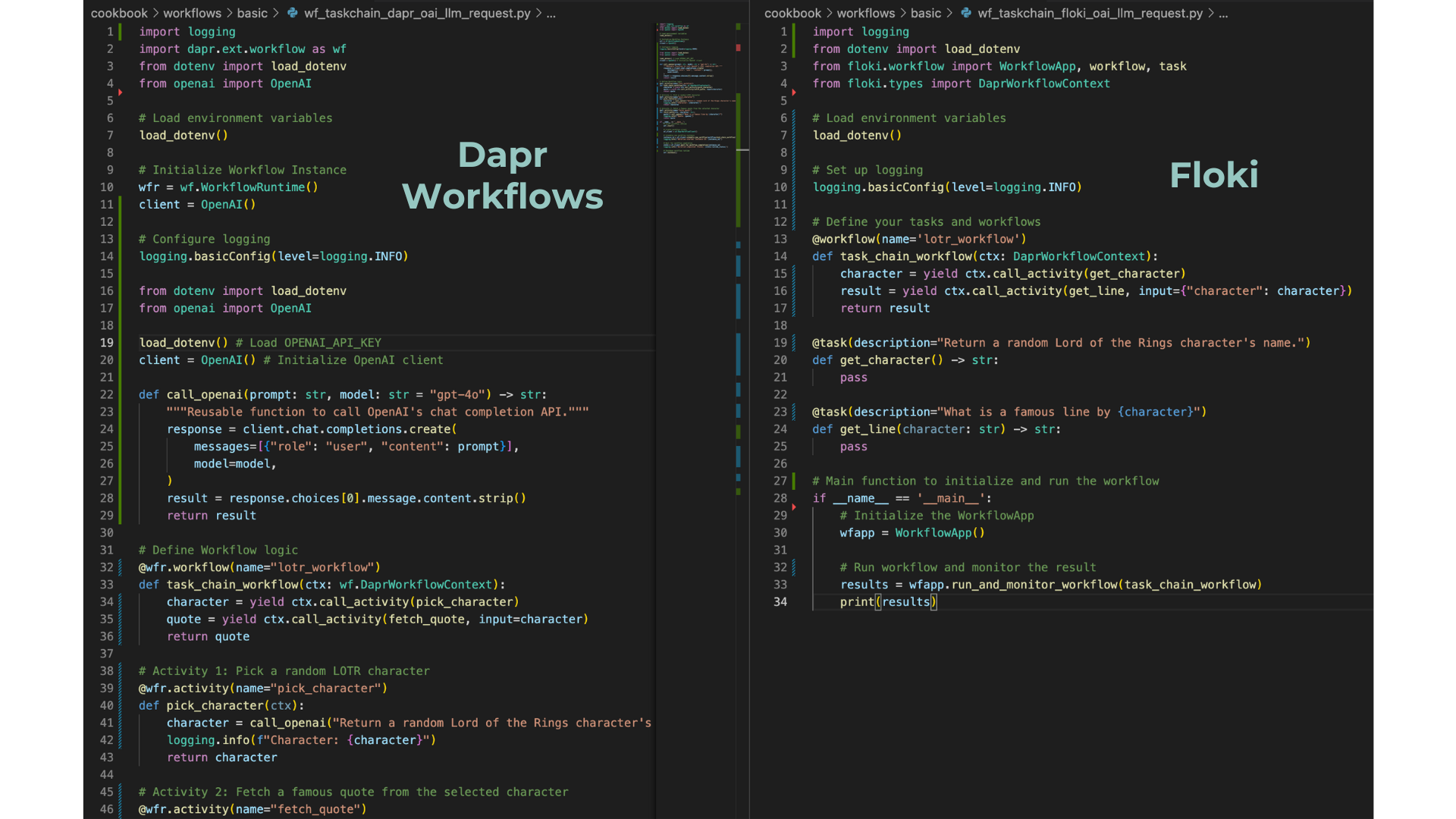
You can use the following code and create a file named app.py:
import logging
from dotenv import load_dotenv
from floki.workflow import WorkflowApp, workflow, task
from floki.types import DaprWorkflowContext
# Load environment variables
load_dotenv()
# Set up logging
logging.basicConfig(level=logging.INFO)
# Define your tasks and workflows
@workflow(name='lotr_workflow')
def task_chain_workflow(ctx: DaprWorkflowContext):
character = yield ctx.call_activity(get_character)
result = yield ctx.call_activity(get_line, input={"character": character})
return result
@task(description="Return a random Lord of the Rings character's name.")
def get_character() -> str:
pass
@task(description="What is a famous line by {character}")
def get_line(character: str) -> str:
pass
# Main function to initialize and run the workflow
if __name__ == '__main__':
# Initialize the WorkflowApp
wfapp = WorkflowApp()
# Run workflow and monitor the result
results = wfapp.run_and_monitor_workflow(task_chain_workflow)
print(results)Save your OPENAI_API_KEY in a .env file and run the workflow with the dapr cli and the following command:
dapr run --app-id llmwf --dapr-grpc-port 50001 - python app.pyYou can also define different LLM inference providers for each task, enabling agentic workflows with multiple language models 🔥.
from floki.llm import OpenAIChatClient
# Load environment variables
load_dotenv()
# Define LLM Clients
azoaillm = OpenAIChatClient(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_deployment="gpt-4o"
)
oaillm = OpenAIChatClient(model="gpt-4o-mini")
# Define your tasks and workflows
@workflow(name='lotr_workflow')
def task_chain_workflow(ctx: DaprWorkflowContext):
character = yield ctx.call_activity(get_character)
result = yield ctx.call_activity(get_line, input={"character": character})
return result
@task(description="Return a random Lord of the Rings character's name.", llm=azoaillm)
def get_character() -> str:
pass
@task(description="What is a famous line by {character}", llm=oaillm)
def get_line(character: str) -> str:
passLeveraging Language Models Structured Outputs ⚡️
When defining workflows with tasks, you can specify the expected output as a structured Pydantic model, which makes it easier to manage and validate the response from LMs. For example, by annotating the output of a task with a Pydantic model, Floki automatically understands that the response should follow the schema defined by that model. This allows Floki to use LLMs' structured outputs, validate them against the model, and convert the results into a dictionary after ensuring that they conform to the expected structure.
Save the following code in a file named structured.py.
import logging
from dotenv import load_dotenv
from pydantic import BaseModel
from floki.workflow import WorkflowApp, workflow, task
from floki.types import DaprWorkflowContext
# Load environment variables
load_dotenv()
# Set up logging
logging.basicConfig(level=logging.INFO)
# Define a Pydantic model to structure the output
class Dog(BaseModel):
name: str
bio: str
breed: str
# Define the workflow
@workflow
def question(ctx: DaprWorkflowContext, input: str):
step1 = yield ctx.call_activity(ask, input=input)
return step1
# Define the task and use Python function annotation for structured output
@task("Who was {name}?")
def ask(name: str) -> Dog:
pass
if __name__ == '__main__':
# Initialize the WorkflowApp
wfapp = WorkflowApp()
# Execute the workflow and monitor its progress
results = wfapp.run_and_monitor_workflow(workflow=question, input="Scooby Doo")
print(results)Save your OPENAI_API_KEY in a .env file and run the workflow with the dapr cli and the following command:
dapr run --app-id llmstructwf --dapr-grpc-port 50001 - python app.pyIntroducing Agents as Dapr Workflows 🤖 🔄 🤖
Throughout this blog, we’ve explored how to define an LM-based orchestrator, use the tool-calling agentic pattern, and enable communication via a messaging pub/sub system. With Floki, all these concepts come together seamlessly, making it incredibly easy to define and manage your orchestrators and agents. By following these agentic patterns, Floki simplifies the process of triggering the right workflows and routing messages to the appropriate agents.
For all the files in the following example, go to https://github.com/Cyb3rWard0g/floki/tree/main/cookbook/workflows/multi_agents/basic_lotr_agents_as_workflows and make sure you enable Redis Insights following these instructions.
The LM-based Orchestrator
from floki import LLMOrchestrator
from dotenv import load_dotenv
import asyncio
import logging
async def main():
try:
agentic_orchestrator = LLMOrchestrator(
name="Orchestrator",
message_bus_name="messagepubsub",
state_store_name="agenticworkflowstate",
state_key="workflow_state",
agents_registry_store_name="agentsregistrystore",
agents_registry_key="agents_registry",
service_port=8009,
daprGrpcPort=50009,
max_iterations=25
)
await agentic_orchestrator.start()
except Exception as e:
print(f"Error starting service: {e}")
if __name__ == "__main__":
load_dotenv()
logging.basicConfig(level=logging.INFO)
asyncio.run(main())The Assistant Agent (Tool-Calling Agentic Pattern)
from floki import AssistantAgent
from dotenv import load_dotenv
import asyncio
import logging
async def main():
try:
# Define Agent
hobbit_agent = AssistantAgent(
name="Frodo",
role="Hobbit",
goal="Carry the One Ring to Mount Doom, resisting its corruptive power while navigating danger and uncertainty.",
instructions=[
"Speak like Frodo, with humility, determination, and a growing sense of resolve.",
"Endure hardships and temptations, staying true to the mission even when faced with doubt.",
"Seek guidance and trust allies, but bear the ultimate burden alone when necessary.",
"Move carefully through enemy-infested lands, avoiding unnecessary risks.",
"Respond concisely, accurately, and relevantly, ensuring clarity and strict alignment with the task."
],
message_bus_name="messagepubsub",
state_store_name="agenticworkflowstate",
state_key="workflow_state",
agents_registry_store_name="agentsregistrystore",
agents_registry_key="agents_registry",
service_port=8001,
daprGrpcPort=50001
)
await hobbit_agent.start()
except Exception as e:
print(f"Error starting service: {e}")
if __name__ == "__main__":
load_dotenv()
logging.basicConfig(level=logging.INFO)
asyncio.run(main())You can define as many agents as you want.
Multi-Agent Run Template 🤖⚡️🤖⚡️🤖⚡️
Just like Dapr's Multi-App Run feature, Floki allows you to define and initialize multiple agents and orchestrators in a single template. This approach lets you manage and run all components, agents, workflows, and orchestrators simultaneously, streamlining the process of testing and deploying multi-agent systems. Whether running locally or in a cloud environment, this template simplifies the setup and execution of complex, multi-agent workflows 🔥.
# https://docs.dapr.io/developing-applications/local-development/multi-app-dapr-run/multi-app-template/#template-properties
version: 1
common:
resourcesPath: ./components
logLevel: info
appLogDestination: console
daprdLogDestination: console
apps:
- appId: HobbitApp
appDirPath: ./services/hobbit/
appPort: 8001
command: ["python3", "app.py"]
daprGRPCPort: 50001
- appId: WizardApp
appDirPath: ./services/wizard/
appPort: 8002
command: ["python3", "app.py"]
daprGRPCPort: 50002
- appId: ElfApp
appDirPath: ./services/elf/
appPort: 8003
command: ["python3", "app.py"]
daprGRPCPort: 50003
- appId: DwarfApp
appDirPath: ./services/dwarf/
appPort: 8004
command: ["python3", "app.py"]
daprGRPCPort: 50004
- appId: RangerApp
appDirPath: ./services/ranger/
appPort: 8007
command: ["python3", "app.py"]
daprGRPCPort: 50007
- appId: EagleApp
appDirPath: ./services/eagle/
appPort: 8008
command: ["python3", "app.py"]
daprGRPCPort: 50008
- appId: LLMOrchestratorApp
appDirPath: ./services/orchestrator/
appPort: 8009
command: ["python3", "app.py"]
daprGRPCPort: 50009Next, you can start the orchestrator and all agents with the following command:
dapr run -f .If you set up Redis Insights as shown in the project docs, you can go to http://localhost:5540/ and see that all agents registered and subscribed to specific topics to listen for specific tasks or broadcast messages.
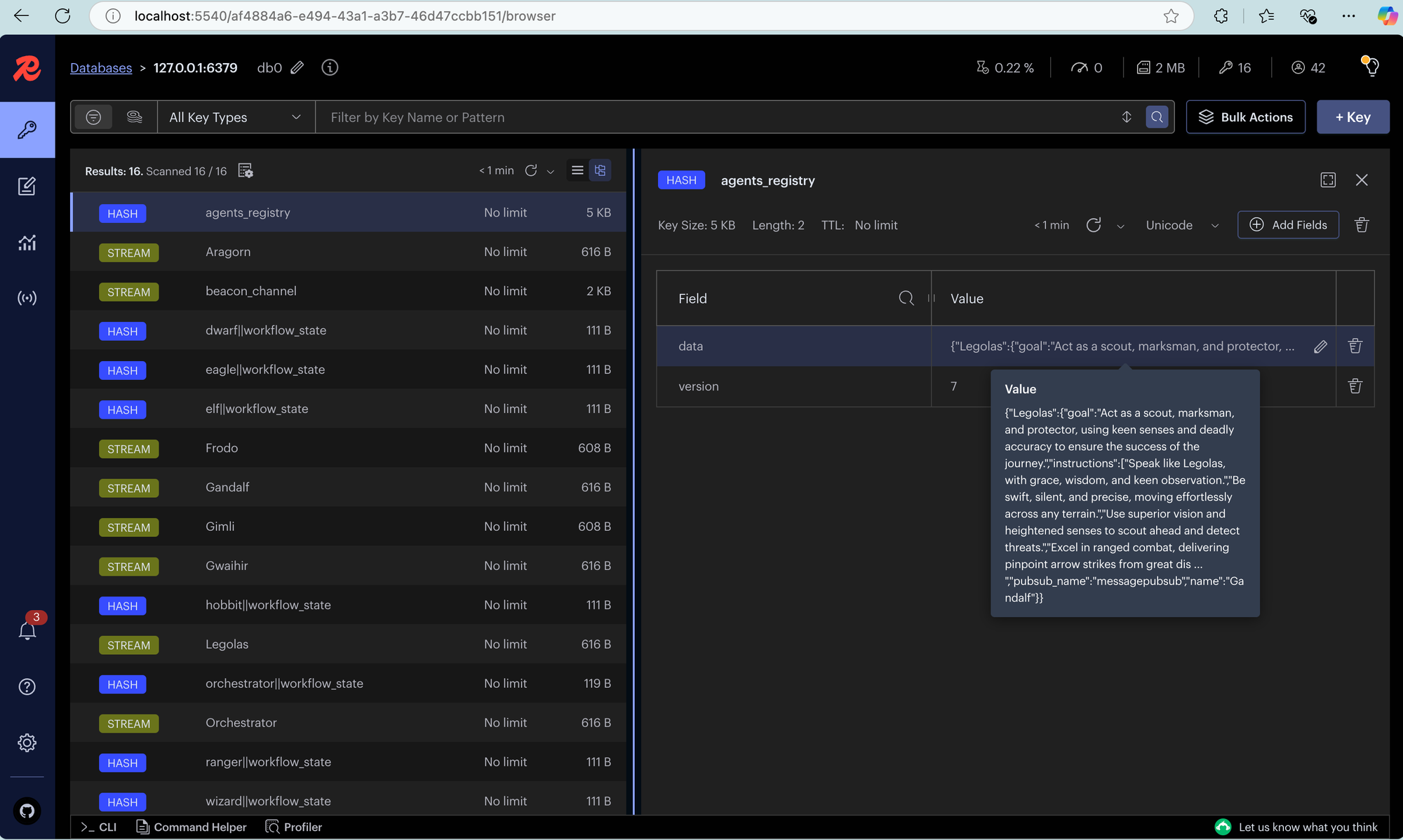
CLI at the bottom left of your Redis dashboard and type flushdb. Then, you can run again dapr run -f .
Trigger the Orchestrator
Finally, you can send a task to the LM-based Orchestrator over port 50009
curl -i -X POST http://localhost:8009/RunWorkflow \
-H "Content-Type: application/json" \
-d '{"task": "Lets solve the riddle to open the Doors of Durin and enter Moria."}'Check the Logs
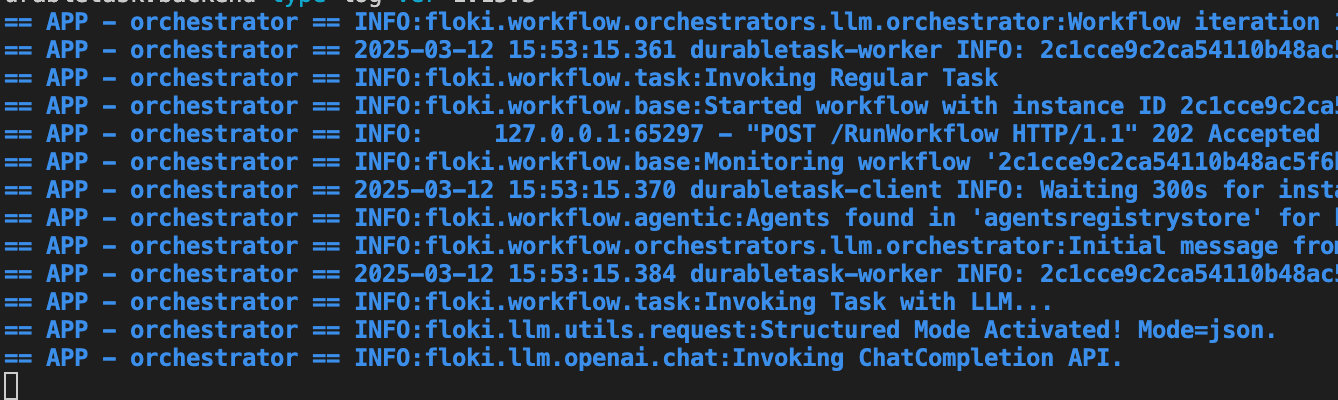
Automatically in your console, you will start seeing inference calls to OpenAI Chat Completion endpoints and more.
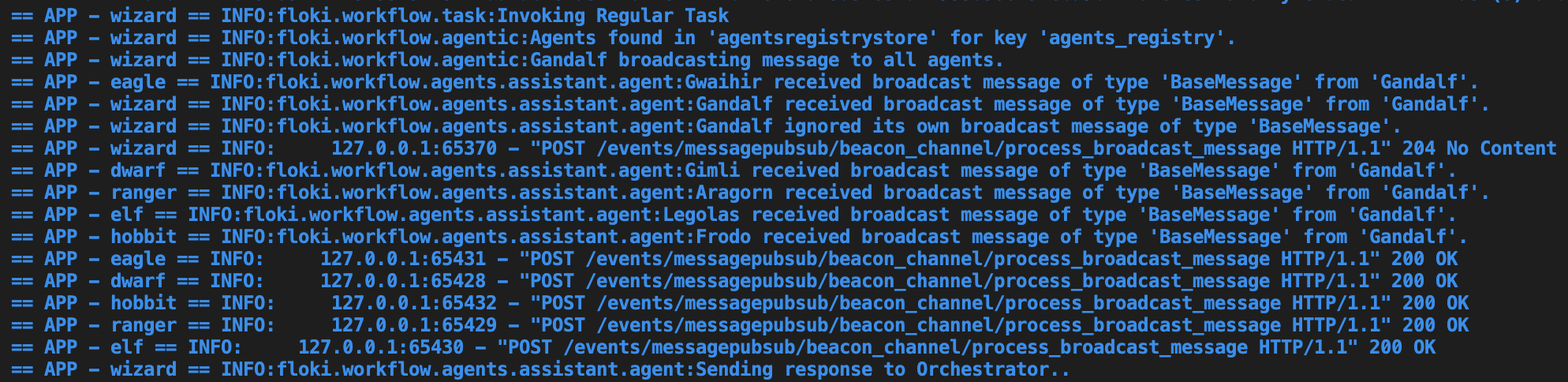
You are going to see agents invoking tasks, broadcasting messages to other agents an sending responses to the orchestrator.
You are going to see the LM-based orchestrator deciding if we continue or not, making updates to the plan on each iteration if needed, etc. 🔥

You can also go to http://localhost:9411/zipkin/ and check the telemetry collected by default over each tasks executed.
Finally, in Floki, the orchestrator saves its state to a local file, which can be found in the same directory where the orchestrator is defined. You can find an example here. It is fascinating to see it going through the whole plan, keeping chat history, updating the plan on each iteration if needed and capturing task completion.


What is Next for Floki? 👁️🗨️
What began with a curiosity to learn more about scalable agentic systems and leveraging proven, production-grade technologies like Dapr, turned into something much greater. After spending weekends experimenting and brainstorming during work sessions, I found that the best way to learn was through building. And that’s how Floki was born—a product of that curiosity, research, and experimentation. What started as a weekend project has since evolved into a framework that has significantly helped me prototype ideas, collaborate with researchers, and share insights. It’s been an incredible journey.
After releasing the framework in 2024, I was fortunate enough to receive incredible feedback from the Dapr team. They were amazed by how I was able to integrate Dapr into an AI agentic framework. After a few fruitful conversations, it became clear that there was an opportunity to take this integration even further. And so, I decided to partner with the Dapr community to bring this research into the Dapr ecosystem.
Announcing Dapr Agents ✨
On March 12th, 2025, Dapr officially announced the release of Dapr Agents in partnership with the Cloud Native Computing Foundation (CNCF). You can read the full release article here and check out the TechCrunch announcement here.
What Does This Mean for Floki? ❤️
With the Dapr Agents release, I’m excited to share that I’ve decided to donate the full Floki codebase to the Dapr community ❤️. This collaboration will help take Floki to the next level by working directly with Dapr maintainers. It’s a monumental milestone for me, as Floki becomes my first open-source project integrated into another amazing open-source ecosystem. It’s truly humbling to see the late-night research and countless hours of hard work now contributing to a project that’s being used by so many developers and companies. The impact is beyond anything I imagined, and I’m incredibly proud of this accomplishment.
From here on, I will continue supporting Dapr Agents while the Floki repo will remain as the foundation of everything that made this integration possible ❤️. The journey is far from over. This is just the beginning, and there’s so much more to do and more features to work on.

Check out Dapr Agents GitHub Repo
https://github.com/Cyb3rWard0g/floki/tree/main
Thank you so much for making it to the end of this blog post! I truly appreciate it and am happy to share my journey with the open-source community. Until next time!

References
- Agentic Design Patterns Part 1: https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance/
- Dapr Workflow Patterns: https://docs.dapr.io/developing-applications/building-blocks/workflow/workflow-patterns/
- Explore AI models: Key differences between small language models and large language models: https://www.microsoft.com/en-us/microsoft-cloud/blog/2024/11/11/explore-ai-models-key-differences-between-small-language-models-and-large-language-models/?msockid=043010783916686820ad045a388f6905&mscm=1
- CloudEvents Specification: https://github.com/cloudevents/spec/tree/v1.0
- CloudEvents: https://cloudevents.io/
- Open Telemetry https://opentelemetry.io/
- W3C Trace Context https://www.w3.org/TR/trace-context/
- Dapr Agents: https://github.com/dapr/dapr-agents